lab1
![]()
Objetivos¶
- Conhecer a biblioteca Sklearn
- Conhecer algoritmos de classificação, K-Nearest Neighbors (KNN) e Árvore de Decisão;
- Aplicar o Grid Search para encontrar os melhores parâmetros para esses modelos;
- Conhecer, Analisar e interpretar métricas de avaliação (acurácia, precisão, recall, F1-score) e visualizações para entender o desempenho dos modelos.
Problemas de classicação¶
A classificação é uma das principais tarefas em aprendizado de máquina e envolve a atribuição de um rótulo ou categoria a um conjunto de dados. Por exemplo, podemos usar a classificação para identificar se um e-mail é spam ou não, se uma transação financeira é fraudulenta ou legítima, ou para prever se um paciente desenvolverá uma doença com base em seus dados médicos.
Existem muitos desafios em problemas de classicação que o análista de dados deve levar em consideração, como a escolha do modelo de aprendizado de máquina adequado, o ajuste dos hiperparâmetros do modelo, a seleção de features relevantes, o tratamento de dados adequado ao problema, o cuidado com overfitting e a avaliação correta do modelo.
Além disso, diferentes modelos de classificação têm seus próprios pontos fortes e fracos, e escolher o modelo certo para um problema específico pode ser difícil.
Resumo sobre KNN e Árvore de Decisão¶
| Algoritmo | Aplicação | Vantagens | Desvantagens | Contexto de uso |
|---|---|---|---|---|
| Árvores de Decisão | Classificação/Regressão | Fácil interpretabilidade, lida bem com dados faltantes, captura relações não lineares | Tendência ao overfitting, pode ser sensível a ruído | Problemas de classificação/regressão com relações não lineares |
| K-Nearest Neighbors (KNN) | Classificação/Regressão | Fácil de entender e implementar, lida bem com dados com muitas variáveis de entrada | Requer muita memória para grandes conjuntos de dados, sensível a outliers | Problemas de classificação/regressão com muitas variáveis de entrada e poucas classes possíveis |
Definição do problema¶
A primeira coisa que precisamos fazer é a definição do problema. Neste primeiro caso vamos trabalhar com o mesmo dataset da última aula, dataset iris. Vamos desenvolver um sistema de machine learning capaz de classificar a especie de flor Iris com base nos dimensionais da pétala e sepala.
Relembrando o dataset Iris¶
Iris é um dataset de flor com 150 linhas, divididos em três espécies diferentes: setosa, versicolor e virginica, sendo 50 amostras de cada espécie. Os atributos de largura e comprimento de sépala e largura e comprimento de pétala de cada flor foram anotados manualmente.

# Inicializção das bibliotecas
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
# Caminho do arquivo
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define o nome das colunas
header = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
# Lê e carrega o arquivo para a memória
df = pd.read_csv(url, header=None, names=header)
# Retorna um trecho com as 5 primeiras linhas do dataframe
df.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
df.tail()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
# Mostra informações sobre o dataframe em si
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal_length 150 non-null float64 1 sepal_width 150 non-null float64 2 petal_length 150 non-null float64 3 petal_width 150 non-null float64 4 species 150 non-null object dtypes: float64(4), object(1) memory usage: 6.0+ KB
# class distribution
print(df.groupby('species').size())
species Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 dtype: int64
Desafio 1¶
Aplique os métodos que achar conveniente (vimos algumas opções na última aula) para visualizar os dados de forma gráfica.
## Sua resposta e seus gráficos para análisar..
PARE!!!¶
A análise feita no desafio 1 é uma das etapas mais importantes. Caso você tenha pulado essa etapa, volte e faça suas análises.
scikit-learn¶
Também conhecida como sklearn, é uma biblioteca de código aberto (open source) para a linguagem Python, essa biblioteca fornece uma ampla gama de ferramentas e algoritmos de aprendizado de máquina de forma acessível e eficiente.

Podemos dizer que o scikit-learn é a ferramenta mais popular e utilizada em aprendizado de máquina e existem alguns motivos para isso, tais como:
- Simplicidade e Consistência: Todos os algoritmos no scikit-learn compartilham uma interface consistente, que segue um padrão de métodos como fit(), predict(), e transform(). Isso facilita a troca e experimentação de diferentes algoritmos, promovendo um ambiente de desenvolvimento rápido e eficiente.
- Compatibilidade e Integração: O scikit-learn é projetado para interoperabilidade com outras bibliotecas do ecossistema Python, como pandas para manipulação de dados, numpy para operações numéricas, e matplotlib para visualização. Essa integração permite uma fácil manipulação e transformação de dados, bem como a visualização de resultados de modelos.
- Foco em Performance e Eficiência Computacional: Embora Python seja uma linguagem interpretada, a scikit-learn faz uso extensivo de operações vetorizadas através de numpy e implementações otimizadas em Cython (que é uma linguagem de programação que facilita a escrita de extensões em C para Python) para acelerar o processamento de dados e a execução de algoritmos. Isso proporciona uma execução eficiente de tarefas complexas de machine learning, como treinamento de modelos e ajuste de hiperparâmetros.
Instalação¶
pip install scikit-learn
Saiba mais: site da documentação oficial https://scikit-learn.org/stable/
# instalando a biblioteca scikit-learn
!pip install scikit-learn --quiet
Codificando os dados¶
Com essa etapa concluída, vamos codificar os rótulos de especie para que possam ser usados pelos modelos que vamos treinar.
LabelEncoder¶
- LabelEncoder: Converte cada categoria em um valor inteiro único. Cada categoria recebe um número inteiro diferente, e os valores numéricos não têm relação direta entre si além de representar categorias distintas. As categorias são ordenadas alfabeticamente e cada categoria recebe um valor correspondente.
# Codificando os rótulos de especies
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['species'] = le.fit_transform(df['species'])
# Verificando o dataframe após a codificação
df.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
df.groupby('species').size()
species 0 50 1 50 2 50 dtype: int64
Dividindo os dados em conjunto de treinamento e de testes¶
Em qualquer projeto de aprendizado de máquina, uma prática essencial é separar os dados em conjuntos de treinamento e teste.
Isso permite treinar o modelo em um subconjunto dos dados e avaliá-lo em outro subconjunto, garantindo que o modelo não seja avaliado nos mesmos dados em que foi treinado.
A função train_test_split facilita esse processo, dividindo os dados em duas ou mais partes de forma aleatória ou estratificada.
O parâmetro test_size define a proporção dos dados reservada para o teste, e o parâmetro random_state garante a reprodutibilidade do processo.
Dividir nosso dataset em dois conjuntos de dados.
Treinamento- Representa80%das amostras do conjunto de dados original.Teste- com20%das amostras
# Separamos 20% para o teste
from sklearn.model_selection import train_test_split
## define entradas de dados e o target
X = df.iloc[:, :-1]
y = df['species']
# Separando os dados em conjunto de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
print(f"Formato das tabelas de dados de treino {X_train.shape} e teste {X_test.shape}")
Formato das tabelas de dados de treino (120, 4) e teste (120,)
#Primeiras linhas do dataframe de treino
X_train.head()
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| 22 | 4.6 | 3.6 | 1.0 | 0.2 |
| 15 | 5.7 | 4.4 | 1.5 | 0.4 |
| 65 | 6.7 | 3.1 | 4.4 | 1.4 |
| 11 | 4.8 | 3.4 | 1.6 | 0.2 |
| 42 | 4.4 | 3.2 | 1.3 | 0.2 |
y_train.tail()
71 1 106 2 14 0 92 1 102 2 Name: species, dtype: int64
Chegou a hora de treinar os modelos¶
Treinar um modelo no python é simples se usar o Scikit-Learn.
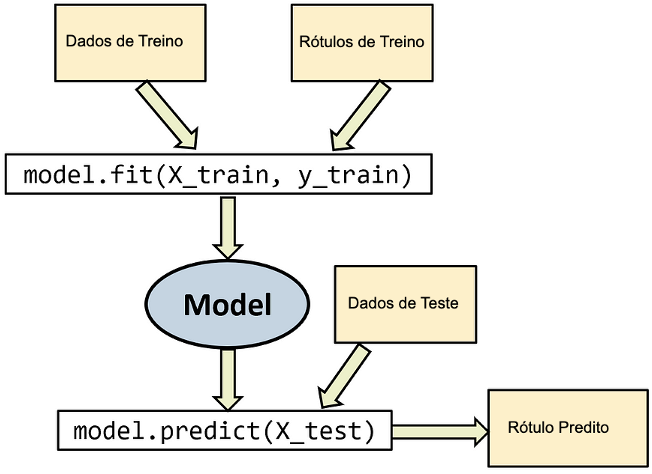
Treinar um modelo no Scikit-Learn é simples: basta criar o classificador, e chamar o método fit().
Uma observação sobre a sintaxe dos classificadores do scikit-learn
- O método
fit(X,Y)recebe uma matriz ou dataframe X onde cada linha é uma amostra de aprendizado, e um array Y contendo as saídas esperadas do classificador, seja na forma de texto ou de inteiros - O método
predict(X)recebe uma matriz ou dataframe X onde cada linha é uma amostra de teste, retornando um array de classes
Treinamento usando algoritmo KNN¶
# Importa a biblioteca
from sklearn.neighbors import KNeighborsClassifier
# Cria o classificar KNN
k = 3
knn = KNeighborsClassifier()
# Cria o modelo de machine learning
knn.fit(X_train, y_train)
KNeighborsClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| n_neighbors | 5 | |
| weights | 'uniform' | |
| algorithm | 'auto' | |
| leaf_size | 30 | |
| p | 2 | |
| metric | 'minkowski' | |
| metric_params | None | |
| n_jobs | None |
Pronto!! bora testar se esta funcionando....
Vamos fazer predições para os dados do conjunto de teste
# Realizando previsões
y_pred = knn.predict(X_test)
# vendo as previsões
print(y_pred)
# com o rótulo original
print("Rótulo original:", le.inverse_transform(y_test))
print("Nova previsão:", le.inverse_transform(y_pred))
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0] Rótulo original: ['Iris-versicolor' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa'] Nova previsão: ['Iris-versicolor' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa']
Predição para novos dados¶
Vamos fazer a predição para uma flor com as seguintes dimensões:
- sepal_length = 5.1
- sepal_width = 3.5
- petal_length = 1.4
- petal_width = 0.2
# novas previsões
sepal_length = 14.1 # altere esses valores para testar
sepal_width = 1.5 # altere esses valores para testar
petal_length = 1.4 # altere esses valores para testar
petal_width = 2.2 # altere esses valores para testar
dado = pd.DataFrame([[sepal_length, sepal_width, petal_length, petal_width]], columns=X.columns)
nova_previsao = knn.predict(dado)
print("Novas previsões:", nova_previsao)
# com o rótulo original
print("Rótulo original:", le.inverse_transform(nova_previsao))
Novas previsões: [1] Rótulo original: ['Iris-versicolor']
# a probabilidade da predição
prob = knn.predict_proba(dado)
print("Probabilidade da predição:", prob)
Probabilidade da predição: [[0. 0.8 0.2]]
Avaliação do modelo treinado¶
A avaliação de modelos é uma etapa importante no pipeline de machine learning.
Para cada tipo de tarefa (classificação, regressão ou clusterização), diferentes métricas são usadas para medir o quão bem o modelo está desempenhando. A seguir, exploramos as principais métricas oferecidas pelo scikit-learn.
Em resumo: Avaliação de Modelos¶
- Acurácia: Percentual de previsões corretas.
- Precisão: Proporção de previsões positivas corretas (evita falsos positivos).
- Recall: Proporção de casos positivos identificados (evita falsos negativos).
- F1-score: Média harmônica de precisão e recall, utilizado para datasets desbalanceados.
# Avaliando o modelo
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
print("Acurácia: ", accuracy_score(y_test, y_pred))
print("Precisão: ", precision_score(y_test, y_pred, average='macro'))
print("Recall: ", recall_score(y_test, y_pred, average='macro'))
print("F1-score: ", f1_score(y_test, y_pred, average='macro'))
## average='macro': métrica é calculada para cada classe individualmente e, em seguida, a média não ponderada das métricas de cada classe é retornada.
## Isso significa que todas as classes têm a mesma importância no cálculo da métrica.
Acurácia: 1.0 Precisão: 1.0 Recall: 1.0 F1-score: 1.0
Treinamento usando algoritmo Árvore de Decisão¶
from sklearn.tree import DecisionTreeClassifier
# Definindo o modelo de árvore de decisão com hiperparâmetros padrão
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)
DecisionTreeClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| criterion | 'gini' | |
| splitter | 'best' | |
| max_depth | None | |
| min_samples_split | 2 | |
| min_samples_leaf | 1 | |
| min_weight_fraction_leaf | 0.0 | |
| max_features | None | |
| random_state | None | |
| max_leaf_nodes | None | |
| min_impurity_decrease | 0.0 | |
| class_weight | None | |
| ccp_alpha | 0.0 | |
| monotonic_cst | None |
# Realizando previsões e avaliando o modelo
y_pred = tree.predict(X_test)
# vendo as previsões
print("Acurácia: ", accuracy_score(y_test, y_pred))
print("Precisão: ", precision_score(y_test, y_pred, average='macro'))
print("Recall: ", recall_score(y_test, y_pred, average='macro'))
print("F1-score: ", f1_score(y_test, y_pred, average='macro'))
Acurácia: 1.0 Precisão: 1.0 Recall: 1.0 F1-score: 1.0
Visualização da árvore¶
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
plt.figure(figsize=(12,8), dpi=400)
plot_tree(tree, feature_names=X.columns, class_names=le.classes_, filled=True)
plt.show()

Predição para novos dados¶
Vamos fazer a predição para uma flor com as seguintes dimensões:
- sepal_length = 5.1
- sepal_width = 3.5
- petal_length = 1.4
- petal_width = 0.2
# novas previsões
sepal_length = 14.1 # altere esses valores para testar
sepal_width = 1.5 # altere esses valores para testar
petal_length = 1.4 # altere esses valores para testar
petal_width = 2.2 # altere esses valores para testar
dado = pd.DataFrame([[sepal_length, sepal_width, petal_length, petal_width]], columns=X.columns)
nova_previsao = tree.predict(dado)
print("Novas previsões:", nova_previsao)
# com o rótulo original
print("Rótulo original:", le.inverse_transform(nova_previsao))
Novas previsões: [0] Rótulo original: ['Iris-setosa']
# a probabilidade da predição
prob = tree.predict_proba(dado)
print("Probabilidade da predição:", prob)
Probabilidade da predição: [[1. 0. 0.]]
Ajustando os hiperparâmetros do modelo KNN¶
Ao ajustar esses hiperparâmetros usando o Grid Search, podemos encontrar a combinação ideal de hiperparâmetros que leva à melhor performance do modelo em um conjunto de dados específico.
Existem vários hiperparâmetros do modelo K-Nearest Neighbors (KNN) que podem ser ajustados usando o Grid Search. Alguns dos hiperparâmetros mais comuns são:
n_neighbors: o número de vizinhos mais próximos a serem considerados no modelo.weights: como ponderar a contribuição dos vizinhos mais próximos. Opções comuns sãouniform, onde todos os vizinhos têm peso igual, edistance, onde o peso é inversamente proporcional à distância do ponto de consulta aos vizinhos.p: a métrica de distância a ser usada. O valor padrão ép=2, que corresponde à distância Euclidiana. Outras opções incluemp=1, que corresponde à distância de Manhattan, ep=inf, que corresponde à distância máxima.algorithm: o algoritmo usado para calcular os vizinhos mais próximos. As opções comuns sãobrute, que força uma busca exaustiva sobre todos os pontos de treinamento, ekd_treeeball_tree, que usam estruturas de dados mais eficientes para acelerar a busca.leaf_size: o tamanho da folha para a árvore de busca, que afeta a eficiência do algoritmo.
from sklearn.model_selection import GridSearchCV
# Definindo os valores para os hiperparâmetros
param_grid = {'n_neighbors': [3, 5, 7, 9], 'weights': ['uniform', 'distance'], 'algorithm': ['ball_tree', 'kd_tree', 'brute'], 'p': [1, 2]}
# Criando o objeto GridSearchCV
grid_knn = GridSearchCV(KNeighborsClassifier(), param_grid, verbose=1, cv=5, n_jobs=-1)
# Ajustando o modelo com os dados de treinamento
grid_knn.fit(X_train, y_train)
Fitting 5 folds for each of 48 candidates, totalling 240 fits
GridSearchCV(cv=5, estimator=KNeighborsClassifier(), n_jobs=-1,
param_grid={'algorithm': ['ball_tree', 'kd_tree', 'brute'],
'n_neighbors': [3, 5, 7, 9], 'p': [1, 2],
'weights': ['uniform', 'distance']},
verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| estimator | KNeighborsClassifier() | |
| param_grid | {'algorithm': ['ball_tree', 'kd_tree', ...], 'n_neighbors': [3, 5, ...], 'p': [1, 2], 'weights': ['uniform', 'distance']} | |
| scoring | None | |
| n_jobs | -1 | |
| refit | True | |
| cv | 5 | |
| verbose | 1 | |
| pre_dispatch | '2*n_jobs' | |
| error_score | nan | |
| return_train_score | False |
KNeighborsClassifier(algorithm='ball_tree', n_neighbors=3, p=1)
Parameters
| n_neighbors | 3 | |
| weights | 'uniform' | |
| algorithm | 'ball_tree' | |
| leaf_size | 30 | |
| p | 1 | |
| metric | 'minkowski' | |
| metric_params | None | |
| n_jobs | None |
# Imprimindo os melhores hiperparâmetros encontrados
print("Melhores hiperparâmetros: ", grid_knn.best_params_)
# Realizando previsões e avaliando o modelo com os melhores hiperparâmetros
y_pred = grid_knn.predict(X_test)
print("Acurácia: ", accuracy_score(y_test, y_pred))
print("Precisão: ", precision_score(y_test, y_pred, average='macro'))
print("Recall: ", recall_score(y_test, y_pred, average='macro'))
print("F1-score: ", f1_score(y_test, y_pred, average='macro'))
Melhores hiperparâmetros: {'algorithm': 'ball_tree', 'n_neighbors': 3, 'p': 1, 'weights': 'uniform'}
Acurácia: 1.0
Precisão: 1.0
Recall: 1.0
F1-score: 1.0
Ajustando os hiperparâmetros do modelo de árvore de decisão¶
Existem vários hiperparâmetros da Árvore de Decisão que podem ser ajustados usando o Grid Search. Alguns dos hiperparâmetros mais comuns são:
criterion: a função usada para medir a qualidade da divisão em cada nó da árvore. As opções comuns sãoginieentropy.splitter: a estratégia usada para escolher a variável que divide o conjunto de dados em cada nó. As opções comuns sãobest, que escolhe a melhor divisão possível, erandom, que escolhe uma divisão aleatória.max_depth: a profundidade máxima da árvore. Se definido comoNone, os nós serão expandidos até que todas as folhas contenham menos de min_samples_split amostras ou todas as amostras sejam classificadas.min_samples_split: o número mínimo de amostras necessárias para dividir um nó interno.min_samples_leaf: o número mínimo de amostras necessárias para ser uma folha.max_features: o número máximo de recursos que podem ser considerados em cada divisão.max_leaf_nodes: o número máximo de folhas permitidas na árvore.
# Definindo os valores para os hiperparâmetros
param_grid = {'criterion': ['gini', 'entropy'], 'max_depth': [None, 3, 5, 7], 'min_samples_split': [2, 5, 10], 'min_samples_leaf': [1, 2, 4]}
# Criando o objeto GridSearchCV
grid_tree = GridSearchCV(DecisionTreeClassifier(), param_grid, verbose=1, cv=5, n_jobs=-1)
# Ajustando o modelo com os dados de treinamento
grid_tree.fit(X_train, y_train)
Fitting 5 folds for each of 72 candidates, totalling 360 fits
GridSearchCV(cv=5, estimator=DecisionTreeClassifier(), n_jobs=-1,
param_grid={'criterion': ['gini', 'entropy'],
'max_depth': [None, 3, 5, 7],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10]},
verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| estimator | DecisionTreeClassifier() | |
| param_grid | {'criterion': ['gini', 'entropy'], 'max_depth': [None, 3, ...], 'min_samples_leaf': [1, 2, ...], 'min_samples_split': [2, 5, ...]} | |
| scoring | None | |
| n_jobs | -1 | |
| refit | True | |
| cv | 5 | |
| verbose | 1 | |
| pre_dispatch | '2*n_jobs' | |
| error_score | nan | |
| return_train_score | False |
DecisionTreeClassifier(criterion='entropy', min_samples_leaf=4)
Parameters
| criterion | 'entropy' | |
| splitter | 'best' | |
| max_depth | None | |
| min_samples_split | 2 | |
| min_samples_leaf | 4 | |
| min_weight_fraction_leaf | 0.0 | |
| max_features | None | |
| random_state | None | |
| max_leaf_nodes | None | |
| min_impurity_decrease | 0.0 | |
| class_weight | None | |
| ccp_alpha | 0.0 | |
| monotonic_cst | None |
# Imprimindo os melhores hiperparâmetros encontrados
print("Melhores hiperparâmetros: ", grid_tree.best_params_)
# Realizando previsões e avaliando o modelo com os melhores hiperparâmetros
y_pred = grid_tree.predict(X_test)
print("Acurácia: ", accuracy_score(y_test, y_pred))
print("Precisão: ", precision_score(y_test, y_pred, average='macro'))
print("Recall: ", recall_score(y_test, y_pred, average='macro'))
print("F1-score: ", f1_score(y_test, y_pred, average='macro'))
Melhores hiperparâmetros: {'criterion': 'entropy', 'max_depth': None, 'min_samples_leaf': 4, 'min_samples_split': 2}
Acurácia: 1.0
Precisão: 1.0
Recall: 1.0
F1-score: 1.0
Comparando os melhores modelos treinados de cada algoritmo¶
Por fim, podemos comparar a performance dos modelos de KNN e árvore de decisão.
# Criando os modelos ( altere os parametros para os melhores hiperparâmetros encontrados)
knn = KNeighborsClassifier(n_neighbors=3, weights='uniform', algorithm='ball_tree', p=1)
tree = DecisionTreeClassifier(criterion='entropy', max_depth=None, min_samples_split=2, min_samples_leaf=4)
# Ajustando os modelos com os dados de treinamento
knn.fit(X_train, y_train)
tree.fit(X_train, y_train)
# Realizando previsões e avaliando os modelos com os dados de teste
knn_pred = knn.predict(X_test)
tree_pred = tree.predict(X_test)
print("KNN - Acurácia: ", accuracy_score(y_test, knn_pred))
print("KNN - Precisão: ", precision_score(y_test, knn_pred, average='macro'))
print("KNN - Recall: ", recall_score(y_test, knn_pred, average='macro'))
print("KNN - F1-score: ", f1_score(y_test, knn_pred, average='macro'))
print("Árvore de Decisão - Acurácia: ", accuracy_score(y_test, tree_pred))
print("Árvore de Decisão - Precisão: ", precision_score(y_test, tree_pred, average='macro'))
print("Árvore de Decisão - Recall: ", recall_score(y_test, tree_pred, average='macro'))
print("Árvore de Decisão - F1-score: ", f1_score(y_test, tree_pred, average='macro'))
KNN - Acurácia: 1.0 KNN - Precisão: 1.0 KNN - Recall: 1.0 KNN - F1-score: 1.0 Árvore de Decisão - Acurácia: 1.0 Árvore de Decisão - Precisão: 1.0 Árvore de Decisão - Recall: 1.0 Árvore de Decisão - F1-score: 1.0
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_test, tree_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=le.classes_)
disp.plot()
plt.title("Matriz de Confusão - Árvore de Decisão")
plt.show()
cm_knn = confusion_matrix(y_test, knn_pred)
disp_knn = ConfusionMatrixDisplay(confusion_matrix=cm_knn, display_labels=le.classes_)
disp_knn.plot(cmap=plt.cm.Blues)
plt.title("Matriz de Confusão - KNN")
plt.show()


Salvando os modelos treinados para uso futuro¶
Após a avaliação, o modelo com melhor desempenho pode ser escolhido para implantação em um ambiente de produção. Iremos fazer em outro código (em breve)
# Salvando os modelos treinados para uso futuro
import joblib
joblib.dump(knn, 'knn_model_iris.pkl')
joblib.dump(tree, 'tree_model_iris.pkl')
['tree_model_iris.pkl']