Lab13 - Mediapipe
Mediapipe¶
Objetivos da aula:
- Apresentar e aplicar a biblioteca
mediapipe
Mediapipe é uma biblioteca de processamento de mídia de código aberto desenvolvida pelo Google, que fornece uma ampla variedade de algoritmos e ferramentas de visão computacional para análise de dados em tempo real.
A biblioteca é implementada em C++ e Python, com suporte para processamento em CPU e GPU.
Entre as funcionalidades oferecidas pela biblioteca Mediapipe, destacam-se a detecção de:
keypoints,tracking,classificação de gestos,reconhecimento facial,pose estimation,detecção de objetos,segmentação de imagem.
A implementação desses algoritmos é feita utilizando técnicas de aprendizado de máquina e redes neurais profundas, incluindo redes neurais convolucionais e redes de grafos.
Primeiros passos¶
O site oficial da documentação do Mediapipe é o https://mediapipe.dev/.
Já existe bastante conteúdo contendo informações detalhadas sobre como utilizar cada uma das funcionalidades da biblioteca, incluindo tutoriais em vídeo e em texto, exemplos de código, e muito mais.
Além disso, a página oferece uma ampla variedade de recursos adicionais, como fóruns de discussão, bibliotecas de modelos pré-treinados, e outros materiais úteis para desenvolvedores de visão computacional.
Instalação¶
A instalação é simples via pip. Para compatibilidade com a nova API (a partir da versão 0.10), use:
pip install mediapipe
> A API mudou nas versões recentes. O código antigo com `mp.solutions` foi depreciado para
> algumas funcionalidades como Face Mesh, que agora usa `mediapipe.tasks`.
O que mudou na biblioteca?¶
Muitos exemplos antigos da internet usam classes como:
!!! warning "Código antigo"
python mp.solutions.face_mesh.FaceMesh() mp.solutions.hands.Hands() mp.solutions.pose.Pose()
Na API atual, a abordagem recomendada é usar Tasks, por exemplo:
FaceLandmarkerHandLandmarkerPoseLandmarker
Essa nova abordagem exige explicitamente um arquivo de modelo .task e a escolha do modo de execução:
IMAGE→ imagem únicaVIDEO→ vídeo ou webcam processados quadro a quadro com timestampLIVE_STREAM→ fluxo contínuo com callback assíncrono
# Descomente se precisar instalar no seu ambiente
# !pip install mediapipe opencv-python matplotlib
Download dos modelos .task¶
A API atual do MediaPipe precisa de modelos compatíveis com cada tarefa.
Neste notebook vamos usar:
face_landmarker.taskhand_landmarker.taskpose_landmarker_heavy.taskblaze_face_short_range.tfliteblaze_face_full_range.tfliteblaze_face_full_range_sparse.tflite
Se os arquivos já estiverem na pasta do notebook, você pode pular esta etapa.
from pathlib import Path
from urllib.request import urlretrieve
MODEL_DIR = Path("models")
MODEL_DIR.mkdir(exist_ok=True)
MODEL_URLS = {
# Landmarkers
"face_landmarker.task": "https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/latest/face_landmarker.task",
"hand_landmarker.task": "https://storage.googleapis.com/mediapipe-models/hand_landmarker/hand_landmarker/float16/latest/hand_landmarker.task",
"pose_landmarker_heavy.task": "https://storage.googleapis.com/mediapipe-models/pose_landmarker/pose_landmarker_heavy/float16/1/pose_landmarker_heavy.task",
# Face Detector
"blaze_face_short_range.tflite": "https://storage.googleapis.com/mediapipe-models/face_detector/blaze_face_short_range/float16/latest/blaze_face_short_range.tflite",
"blaze_face_full_range.tflite": "https://storage.googleapis.com/mediapipe-models/face_detector/blaze_face_full_range/float16/latest/blaze_face_full_range.tflite",
"blaze_face_full_range_sparse.tflite": "https://storage.googleapis.com/mediapipe-models/face_detector/blaze_face_full_range/float16/latest/blaze_face_full_range_sparse.tflite"
}
for filename, url in MODEL_URLS.items():
destination = MODEL_DIR / filename
if not destination.exists():
print(f"Baixando {filename}...")
urlretrieve(url, destination)
else:
print(f"{filename} já existe.")
face_landmarker.task já existe. hand_landmarker.task já existe. pose_landmarker_heavy.task já existe. Baixando blaze_face_short_range.tflite... Baixando blaze_face_full_range.tflite... Baixando blaze_face_full_range_sparse.tflite...
Face detection em imagem¶
Vamos começar com uma imagem estática.
Esse é o melhor cenário para entender a estrutura do resultado, uso básico usando o create_from_model_path(...).
Fluxo lógico¶
- ler a imagem com OpenCV;
- converter de BGR para RGB;
- criar um objeto
mp.Image; # que é o formato esperado pela API do MediaPipe - executar
detect(...); - desenhar as faces encontradas.
import cv2
import matplotlib.pyplot as plt
import mediapipe as mp
# Configurações do MediaPipe
FaceDetector = mp.tasks.vision.FaceDetector
# Define o caminho do modelo que queremos usar
model_path = "models/blaze_face_full_range.tflite"
# estanciando o detector com o modelo escolhido
detector = FaceDetector.create_from_model_path(model_path)
# carregando a imagem e convertendo para o formato esperado pelo MediaPipe
image = cv2.imread("image.png")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb) # Convertendo para o formato esperado pelo MediaPipe
# realizando a detecção
detection_result = detector.detect(mp_image)
# vamos estudar o resultado da detecção
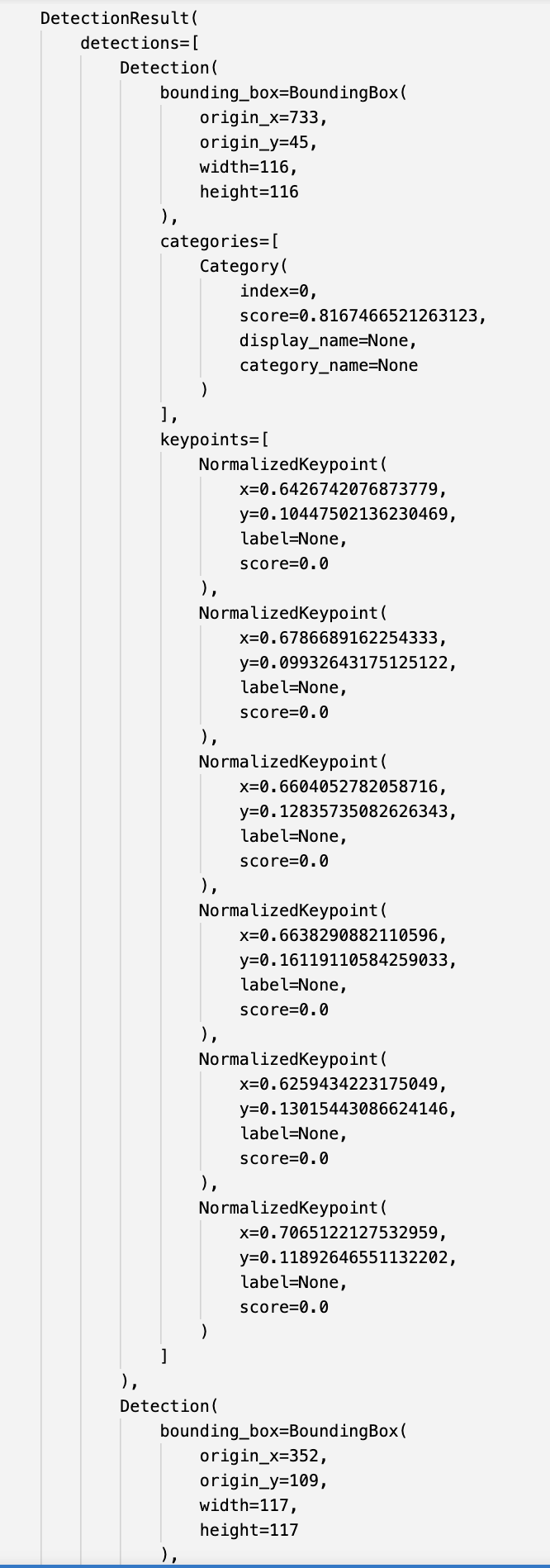
print("Resultado da detecção:")
print(detection_result)
print(f"\nForam encontradas: {len(detection_result.detections)} faces na imagem")
Resultado da detecção: DetectionResult(detections=[Detection(bounding_box=BoundingBox(origin_x=733, origin_y=45, width=116, height=116), categories=[Category(index=0, score=0.8167466521263123, display_name=None, category_name=None)], keypoints=[NormalizedKeypoint(x=0.6426742076873779, y=0.10447502136230469, label=None, score=0.0), NormalizedKeypoint(x=0.6786689162254333, y=0.09932643175125122, label=None, score=0.0), NormalizedKeypoint(x=0.6604052782058716, y=0.12835735082626343, label=None, score=0.0), NormalizedKeypoint(x=0.6638290882110596, y=0.16119110584259033, label=None, score=0.0), NormalizedKeypoint(x=0.6259434223175049, y=0.13015443086624146, label=None, score=0.0), NormalizedKeypoint(x=0.7065122127532959, y=0.11892646551132202, label=None, score=0.0)]), Detection(bounding_box=BoundingBox(origin_x=352, origin_y=109, width=117, height=117), categories=[Category(index=0, score=0.8117252588272095, display_name=None, category_name=None)], keypoints=[NormalizedKeypoint(x=0.32747331261634827, y=0.18185538053512573, label=None, score=0.0), NormalizedKeypoint(x=0.3656294345855713, y=0.187325119972229, label=None, score=0.0), NormalizedKeypoint(x=0.3434414565563202, y=0.21675345301628113, label=None, score=0.0), NormalizedKeypoint(x=0.3433360755443573, y=0.2452930212020874, label=None, score=0.0), NormalizedKeypoint(x=0.30935728549957275, y=0.1953052580356598, label=None, score=0.0), NormalizedKeypoint(x=0.39283981919288635, y=0.20473289489746094, label=None, score=0.0)])]) Foram encontradas: 2 faces na imagem
I0000 00:00:1776353666.934986 3944260 gl_context.cc:407] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M2 INFO: Created TensorFlow Lite XNNPACK delegate for CPU. W0000 00:00:1776353666.939467 3944262 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.
visualizando a saida da detecção mais bonitinha....¶
# para pegar as coordenadas do bounding box de cada face detectada, podemos acessar a propriedade `bounding_box` de cada detecção
x = detection_result.detections[0].bounding_box.origin_x
y = detection_result.detections[0].bounding_box.origin_y
largura = detection_result.detections[0].bounding_box.width
altura = detection_result.detections[0].bounding_box.height
print(f"\nCoordenadas da primeira face detectada:")
print(f"X: {x}, Y: {y}, Largura: {largura}, Altura: {altura}")
# Vamos usar um laço for para visualizar os resultados
for detection in detection_result.detections:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(image_rgb, start_point, end_point, (0, 255, 0), 2)
plt.imshow(image_rgb)
plt.show()
Coordenadas da primeira face detectada: X: 733, Y: 45, Largura: 116, Altura: 116

score = detection_result.detections[0].categories[0].score
print(f"\nScore de confiança da primeira detecção: {score:.2f}")
# agora vamos adicionar o score de confiança da detecção para cada face detectada
for detection in detection_result.detections:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(image_rgb, start_point, end_point, (0, 255, 0), 2)
# Adicionando o score de confiança
score = detection.categories[0].score # Pegando o score da categoria mais provável
label = f"{score:.2f}" # Formatando o score para duas casas decimais
cv2.putText(image_rgb, label, (start_point[0], start_point[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
plt.imshow(image_rgb)
plt.show()
Score de confiança da primeira detecção: 0.82

Keypoints¶
O MediaPipe Face Detector retorna um conjunto de keypoints para cada face detectada, que representam pontos específicos no rosto, como os olhos, nariz, boca, etc.
Esses keypoints são normalizados em relação ao tamanho da imagem, ou seja, seus valores estão entre 0 e 1.
para obter as coordenadas reais dos keypoints, é necessário multiplicar os valores normalizados pelas dimensões da imagem.
# agora para usar os keypoints, precisamos primeiro entender o que são os keypoints.
ponto_x = detection_result.detections[0].keypoints[0].x
ponto_y = detection_result.detections[0].keypoints[0].y
print(f"\nCoordenadas do primeiro keypoint da primeira detecção (normalizado): X: {ponto_x}, Y: {ponto_y}")
h,w,_ = image_rgb.shape
# agora vamos adicionar os keypoints básicos de cada face detectada
for detection in detection_result.detections:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(image_rgb, start_point, end_point, (0, 255, 0), 2)
# Adicionando o score de confiança
score = detection.categories[0].score # Pegando o score da categoria mais provável
label = f"{score:.2f}" # Formatando o score para duas casas decimais
cv2.putText(image_rgb, label, (start_point[0], start_point[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# Adicionando os keypoints básicos
for keypoint in detection.keypoints:
keypoint_x = int(keypoint.x * w)
keypoint_y = int(keypoint.y * h)
cv2.circle(image_rgb, (keypoint_x, keypoint_y), 5, (255, 0, 0), -1) # Desenhando um círculo para cada keypoint
plt.imshow(image_rgb)
plt.show()
Coordenadas do primeiro keypoint da primeira detecção (normalizado): X: 0.6426742076873779, Y: 0.10447502136230469

import cv2
import matplotlib.pyplot as plt
import mediapipe as mp
# Configurações do MediaPipe
FaceDetector = mp.tasks.vision.FaceDetector
# Define o caminho do modelo que queremos usar
model_path = "models/blaze_face_full_range.tflite"
# estanciando o detector com o modelo escolhido
detector = FaceDetector.create_from_model_path(model_path)
# carregando a imagem e convertendo para o formato esperado pelo MediaPipe
image = cv2.imread("faces.png")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h,w,_ = image_rgb.shape
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb) # Convertendo para o formato esperado pelo MediaPipe
# realizando a detecção
detection_result = detector.detect(mp_image)
for detection in detection_result.detections:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(image_rgb, start_point, end_point, (255, 255, 0), 2)
# Adicionando o score de confiança
score = detection.categories[0].score # Pegando o score da categoria mais provável
label = f"{score:.2f}" # Formatando o score para duas casas decimais
cv2.putText(image_rgb, label, (start_point[0], start_point[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 0), 2)
# Adicionando os keypoints básicos
for keypoint in detection.keypoints:
keypoint_x = int(keypoint.x * w)
keypoint_y = int(keypoint.y * h)
cv2.circle(image_rgb, (keypoint_x, keypoint_y), 5, (255, 0, 0), -1) # Desenhando um círculo para cada keypoint
plt.imshow(image_rgb)
plt.show()
I0000 00:00:1776353763.623412 3947177 gl_context.cc:407] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M2 W0000 00:00:1776353763.628001 3947185 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.

Desafio¶
Use a imagem faces.png para testar o código.

Altere o código para determinar qual das faces da imagem está olhando para camera com a cabeça inclina.
Dica: para determinar a direção da cabeça, você deve usar os keypoints do rosto para calcular a posição relativa dos olhos, nariz e boca.
import numpy as np
def calcular_inclinacao_olhos(keypoints):
olho_esq = keypoints[0]
olho_dir = keypoints[1]
dx = olho_dir.x - olho_esq.x
dy = olho_dir.y - olho_esq.y
inclinacao = np.degrees(np.arctan2(dy, dx))
return inclinacao
# calcula inclinaçao da cabeça e retorna o valor da inclinação em torno de zero graus, onde valores positivos indicam inclinação para a direita e valores negativos indicam inclinação para a esquerda
def calcular_inclinacao(keypoints):
# vamos pegar os keypoints da boca e do nariz para calcular a inclinação da cabeça
nariz = keypoints[2] # Supondo que o keypoint 1 seja o nariz
boca = keypoints[3] # Supondo que o keypoint 2 seja a boca
#valor da inclinação em torno de zero graus, onde valores positivos indicam inclinação para a direita e valores negativos indicam inclinação para a esquerda
inclinacao = np.arctan2(boca.y - nariz.y, boca.x - nariz.x) * (180.0 / np.pi) # Convertendo para graus
# ajuste para que a inclinação seja em torno de zero graus, onde valores positivos indicam inclinação para a direita e valores negativos indicam inclinação para a esquerda
inclinacao = inclinacao - 90 # Ajustando para que a inclinação seja
return inclinacao
# para determinar qual a face está com a cabeça inclinada,
# podemos usar os keypoints para calcular a inclinação da cabeça.
import cv2
import matplotlib.pyplot as plt
import mediapipe as mp
# Configurações do MediaPipe
FaceDetector = mp.tasks.vision.FaceDetector
# Define o caminho do modelo que queremos usar
model_path = "models/blaze_face_full_range.tflite"
# estanciando o detector com o modelo escolhido
detector = FaceDetector.create_from_model_path(model_path)
# carregando a imagem e convertendo para o formato esperado pelo MediaPipe
image = cv2.imread("cbjr.png")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h,w,_ = image_rgb.shape
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb) # Convertendo para o formato esperado pelo MediaPipe
# realizando a detecção
detection_result = detector.detect(mp_image)
for detection in detection_result.detections:
inclinacao = calcular_inclinacao_olhos(detection.keypoints)
print(f"Inclinação da cabeça: {inclinacao:.2f}")
if abs(inclinacao) > 5:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(image_rgb, start_point, end_point, (255, 255, 0), 2)
# Adicionando o score de confiança
score = detection.categories[0].score # Pegando o score da categoria mais provável
label = f"{score:.2f}" # Formatando o score para duas casas decimais
cv2.putText(image_rgb, label, (start_point[0], start_point[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 0), 2)
# Adicionando os keypoints básicos
indice = 0
for keypoint in detection.keypoints:
keypoint_x = int(keypoint.x * w)
keypoint_y = int(keypoint.y * h)
cv2.circle(image_rgb, (keypoint_x, keypoint_y), 5, (255, 0, 0), -1) # Desenhando um círculo para cada keypoint
cv2.putText(image_rgb, str(indice), (keypoint_x + 5, keypoint_y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 1) # Adicionando o índice do keypoint
indice += 1
plt.imshow(image_rgb)
plt.show()
Inclinação da cabeça: -7.12 Inclinação da cabeça: 3.06 Inclinação da cabeça: 5.77 Inclinação da cabeça: -2.05
I0000 00:00:1776393029.816865 4509353 gl_context.cc:407] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M2 W0000 00:00:1776393029.821275 4509355 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.

Nota sobre o uso de with¶
Nos exemplos da documentação oficial, o MediaPipe costuma ser usado com with ... as ...: ao criar a task, por exemplo o detector.
Isso acontece porque o objeto da task usa recursos internos da biblioteca e o with ajuda a abrir e encerrar esses recursos automaticamente ao entrar e sair do bloco.
Neste primeiro exemplo que fizemos, optamos por não usar with para manter o foco no fluxo principal da detecção. Mais agora, veremos essa forma mais completa e recomendada.
Em termos simples¶
Você pode pensar assim:
- sem with: eu crio o detector e preciso me preocupar mais com o ciclo de vida dele;
- com with: eu digo “use esse detector só dentro deste bloco” e, ao terminar, a biblioteca fecha o que for necessário automaticamente.
import cv2
import matplotlib.pyplot as plt
import mediapipe as mp
# Configurações do MediaPipe
FaceDetector = mp.tasks.vision.FaceDetector
# Define o caminho do modelo que queremos usar
model_path = "models/blaze_face_full_range.tflite"
# carregando a imagem e convertendo para o formato esperado pelo MediaPipe
image = cv2.imread("faces.png")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h,w,_ = image_rgb.shape
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb)
# usando with para estanciar o detector com o modelo escolhido
with FaceDetector.create_from_model_path(model_path) as detector: ### essa é a novidade, usando with
## esse bloco está igual o que fizemos antes, mas agora o detector só existe dentro desse bloco, e a biblioteca cuida de abrir e fechar os recursos necessários para ele
detection_result = detector.detect(mp_image)
for detection in detection_result.detections:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(image_rgb, start_point, end_point, (255, 255, 0), 2)
# Adicionando o score de confiança
score = detection.categories[0].score # Pegando o score da categoria mais provável
label = f"{score:.2f}" # Formatando o score para duas casas decimais
cv2.putText(image_rgb, label, (start_point[0], start_point[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 0), 2)
# Adicionando os keypoints básicos
for keypoint in detection.keypoints:
keypoint_x = int(keypoint.x * w)
keypoint_y = int(keypoint.y * h)
cv2.circle(image_rgb, (keypoint_x, keypoint_y), 5, (255, 0, 0), -1) # Desenhando um círculo para cada keypoint
plt.imshow(image_rgb)
plt.show()
I0000 00:00:1775819299.757746 2133102 gl_context.cc:407] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M2 W0000 00:00:1775819299.761620 2133104 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.
Face detection modo completo¶
Conhecemos e usamos o método create_from_model_path(...) que é uma forma rápida de criar um detector, mas ele assume que você quer usar o modelo pré-definido para imagens.
os modelos pré-definidos são otimizados para cenários específicos, mas a API do MediaPipe é muito flexível e permite criar detectores personalizados usando o método create_from_options(...). esses parametros sao definidos usando a classe FaceDetectorOptions. assim, você pode configurar o detector escolhido para diferentes cenários de uso, como:
IMAGEVIDEOLIVE_STREAM
import cv2
import mediapipe as mp
import matplotlib.pyplot as plt
# carregando a imagem e convertendo para o formato esperado pelo MediaPipe
image = cv2.imread("faces.png")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h,w,_ = image_rgb.shape
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb)
# Atalhos da API atual
BaseOptions = mp.tasks.BaseOptions
FaceDetector = mp.tasks.vision.FaceDetector
FaceDetectorOptions = mp.tasks.vision.FaceDetectorOptions
RunningMode = mp.tasks.vision.RunningMode
# Define o caminho do modelo que queremos usar
model_path = "models/blaze_face_full_range.tflite"
# Configuração do detector
options = FaceDetectorOptions(
base_options=BaseOptions(model_asset_path=model_path),
running_mode=RunningMode.IMAGE, # ou RunningMode.VIDEO ou RunningMode.LIVE_STREAM
min_detection_confidence=0.4 # mais permissivo para teste
)
# Cria o detector
with FaceDetector.create_from_options(options) as detector:
## esse bloco está igual o que fizemos antes, mas agora o detector só existe dentro desse bloco, e a biblioteca cuida de abrir e fechar os recursos necessários para ele
detection_result = detector.detect(mp_image)
for detection in detection_result.detections:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(image_rgb, start_point, end_point, (255, 255, 0), 2)
# Adicionando o score de confiança
score = detection.categories[0].score # Pegando o score da categoria mais provável
label = f"{score:.2f}" # Formatando o score para duas casas decimais
cv2.putText(image_rgb, label, (start_point[0], start_point[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 0), 2)
# Adicionando os keypoints básicos
for keypoint in detection.keypoints:
keypoint_x = int(keypoint.x * w)
keypoint_y = int(keypoint.y * h)
cv2.circle(image_rgb, (keypoint_x, keypoint_y), 5, (255, 0, 0), -1) # Desenhando um círculo para cada keypoint
plt.imshow(image_rgb)
plt.show()
I0000 00:00:1776355498.651342 4002005 gl_context.cc:407] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M2 W0000 00:00:1776355498.654620 4002011 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.
Desafio¶
Use a imagem cbjr.png para este desafio.

O código a seguir não conseguiu fazer a deteção correta de todos as faces da imagem.
Altere o código para corrigir a detecção e os landmarks.
import cv2
import mediapipe as mp
import matplotlib.pyplot as plt
# carregando a imagem e convertendo para o formato esperado pelo MediaPipe
image = cv2.imread("cbjr.png")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h,w,_ = image_rgb.shape
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb)
# Atalhos da API atual
BaseOptions = mp.tasks.BaseOptions
FaceDetector = mp.tasks.vision.FaceDetector
FaceDetectorOptions = mp.tasks.vision.FaceDetectorOptions
RunningMode = mp.tasks.vision.RunningMode
# Define o caminho do modelo que queremos usar
model_path = "models/blaze_face_full_range_sparse.tflite"
# Configuração do detector
options = FaceDetectorOptions(
base_options=BaseOptions(model_asset_path=model_path),
running_mode=RunningMode.IMAGE, # ou RunningMode.VIDEO ou RunningMode.LIVE_STREAM
min_detection_confidence=0.3, # mais permissivo para teste
)
# Cria o detector
with FaceDetector.create_from_options(options) as detector:
detection_result = detector.detect(mp_image)
for detection in detection_result.detections:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(image_rgb, start_point, end_point, (255, 255, 0), 2)
# Adicionando o score de confiança
score = detection.categories[0].score
label = f"{score:.2f}"
cv2.putText(image_rgb, label, (start_point[0], start_point[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 0), 2)
# Adicionando os keypoints básicos
for keypoint in detection.keypoints:
keypoint_x = int(keypoint.x * w)
keypoint_y = int(keypoint.y * h)
cv2.circle(image_rgb, (keypoint_x, keypoint_y), 5, (255, 0, 0), -1) # Desenhando um círculo para cada keypoint
plt.imshow(image_rgb)
plt.show()
I0000 00:00:1776393213.790542 4512729 gl_context.cc:407] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M2 W0000 00:00:1776393213.815769 4512732 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.

Detecção em Vídeo¶
Para detecção em vídeo, o processo é semelhante ao que fizemos para imagens, as principais diferenças na implementação para vídeo são:
- configuração do
running_modeparaVIDEO - uso de um loop para ler os quadros do vídeo e processá-los em tempo real.
- processamento de cada quadro com
timestamppara garantir a sincronização correta. - uso de
detect_for_video(...)em vez dedetect(...)para processar os quadros do vídeo. - uso de
time.perf_counter()para calcular o timestamp dos quadros e garantir a sincronização correta com o modelo de vídeo.
def estimar_direcao_rosto(keypoints, limiar_horizontal=10, limiar_vertical=10):
"""
Estima a direção do rosto com base em keypoints faciais.
Espera:
keypoints[0] = olho esquerdo
keypoints[1] = olho direito
keypoints[2] = nariz
keypoints[3] = boca
Retorna uma string como:
'frente', 'esquerda', 'direita', 'cima', 'baixo',
'cima-esquerda', 'baixo-direita', etc.
"""
olho_esq = keypoints[0]
olho_dir = keypoints[1]
nariz = keypoints[2]
boca = keypoints[3]
# centro entre os olhos
centro_olhos_x = (olho_esq.x + olho_dir.x) / 2.0
centro_olhos_y = (olho_esq.y + olho_dir.y) / 2.0
# deslocamento do nariz em relação ao centro dos olhos
dx = nariz.x - centro_olhos_x
dy = nariz.y - centro_olhos_y
direcao_horizontal = "frente"
direcao_vertical = ""
# horizontal
if dx > limiar_horizontal:
direcao_horizontal = "direita"
elif dx < -limiar_horizontal:
direcao_horizontal = "esquerda"
# vertical
# como em imagem y cresce para baixo:
# nariz muito abaixo do centro pode indicar cabeça para baixo
# nariz menos abaixo pode indicar cabeça para cima
if dy > limiar_vertical:
direcao_vertical = "baixo"
elif dy < -limiar_vertical:
direcao_vertical = "cima"
# combinação final
if direcao_horizontal == "frente" and direcao_vertical == "":
return "frente"
elif direcao_horizontal != "frente" and direcao_vertical == "":
return direcao_horizontal
elif direcao_horizontal == "frente" and direcao_vertical != "":
return direcao_vertical
else:
return f"{direcao_vertical}-{direcao_horizontal}"
import cv2
import mediapipe as mp
import time
cap = cv2.VideoCapture(1)
# Atalhos da API atual
BaseOptions = mp.tasks.BaseOptions
FaceDetector = mp.tasks.vision.FaceDetector
FaceDetectorOptions = mp.tasks.vision.FaceDetectorOptions
RunningMode = mp.tasks.vision.RunningMode
# Define o caminho do modelo que queremos usar
model_path = "models/blaze_face_full_range.tflite"
# Configuração do detector
options = FaceDetectorOptions(
base_options=BaseOptions(model_asset_path=model_path),
running_mode=RunningMode.VIDEO, # ou RunningMode.VIDEO ou RunningMode.LIVE_STREAM
min_detection_confidence=0.4,
)
# Cria o detector
with FaceDetector.create_from_options(options) as detector:
start_time = time.perf_counter() # Para calcular o timestamp dos frames
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("Não foi possível capturar o vídeo")
break
frame = cv2.flip(frame, 1)
h,w,_ = frame.shape
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame)
timestamp_ms = int((time.perf_counter() - start_time) * 1000)
detection_result = detector.detect_for_video(mp_image, timestamp_ms=timestamp_ms)
for detection in detection_result.detections:
bbox = detection.bounding_box
start_point = (int(bbox.origin_x), int(bbox.origin_y))
end_point = (int(bbox.origin_x + bbox.width), int(bbox.origin_y + bbox.height))
cv2.rectangle(frame, start_point, end_point, (255, 255, 0), 2)
# Adicionando o score de confiança
score = detection.categories[0].score
label = f"{score:.2f}"
cv2.putText(frame, label, (start_point[0], start_point[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 0), 2)
# Adicionando os keypoints básicos
for keypoint in detection.keypoints:
keypoint_x = int(keypoint.x * w)
keypoint_y = int(keypoint.y * h)
cv2.circle(frame, (keypoint_x, keypoint_y), 5, (255, 0, 0), -1) # Desenhando um círculo para cada keypoint
cv2.imshow('Face Detection', frame)
if cv2.waitKey(5) & 0xFF == 27: # Pressione 'Esc' para sair
break
cap.release()
cv2.destroyAllWindows()
I0000 00:00:1776358460.258978 4085148 gl_context.cc:407] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M2 INFO: Created TensorFlow Lite XNNPACK delegate for CPU. W0000 00:00:1776358460.269823 4085149 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.
O Kernel deu pane ao executar o código na célula atual ou em uma célula anterior. Analise o código nas células para identificar uma possível causa da pane. Clique <a href='https://aka.ms/vscodeJupyterKernelCrash'>aqui</a> para obter mais informações. Consulte Jupyter <a href='command:jupyter.viewOutput'>log</a> para obter mais detalhes.
Face Landmarker em imagem¶
O MediaPipe Face Landmarker é o recurso atualizado para detecção e rastreamento de faces. Ele detecta landmarks faciais (478 pontos) e pode inferir expressões faciais.
Importante: garanta que você já fez o download do modelo pré-treinado: https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task
import cv2
import mediapipe as mp
import matplotlib.pyplot as plt
# carregando a imagem e convertendo para o formato esperado pelo MediaPipe
image = cv2.imread("faces.png")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h,w,_ = image_rgb.shape
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb)
# Atalhos da API atual
BaseOptions = mp.tasks.BaseOptions
FaceLandmarker = mp.tasks.vision.FaceLandmarker
FaceLandmarkerOptions = mp.tasks.vision.FaceLandmarkerOptions
VisionRunningMode = mp.tasks.vision.RunningMode
# Caminho para o modelo baixado
model_path = 'face_landmarker.task' # Ajuste se necessário
options = FaceLandmarkerOptions(
base_options=BaseOptions(model_asset_path=model_path),
num_faces=2,
running_mode=VisionRunningMode.IMAGE)
# Crie o landmarker
with FaceLandmarker.create_from_options(options) as landmarker:
# Detecte landmarks
result = landmarker.detect(mp_image)
faces_found = result.face_landmarks
print(f'Foram encontradas: {len(faces_found)} faces na imagem')
if faces_found:
# Crie uma cópia da imagem
annotated_image = image.copy()
# Desenhe os landmarks (simples, sem conexões como no antigo)
for facial_landmarks in faces_found:
for landmark in facial_landmarks:
x = int(landmark.x * image.shape[1])
y = int(landmark.y * image.shape[0])
cv2.circle(annotated_image, (x, y), 1, (0, 255, 0), -1)
# Plote a imagem
plt.figure(figsize=(10, 10))
plt.imshow(cv2.cvtColor(annotated_image, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
Foram encontradas: 2 faces na imagem
W0000 00:00:1776359211.286798 4104464 face_landmarker_graph.cc:180] Sets FaceBlendshapesGraph acceleration to xnnpack by default. I0000 00:00:1776359211.294000 4104464 gl_context.cc:407] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M2 W0000 00:00:1776359211.294988 4104466 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors. W0000 00:00:1776359211.302451 4104470 inference_feedback_manager.cc:121] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.

Desafio¶
Adapte o código acima para funcionar com webcam em tempo real, usando modo VIDEO.
### seu código aqui...
Desafio¶
Implemente uma solução que detecta se os olhos da pessoa estão abertos ou fechados, usando o Eye Aspect Ratio (EAR) baseado nos landmarks faciais.
### seu código aqui...