Lab04 - MLP
![]()
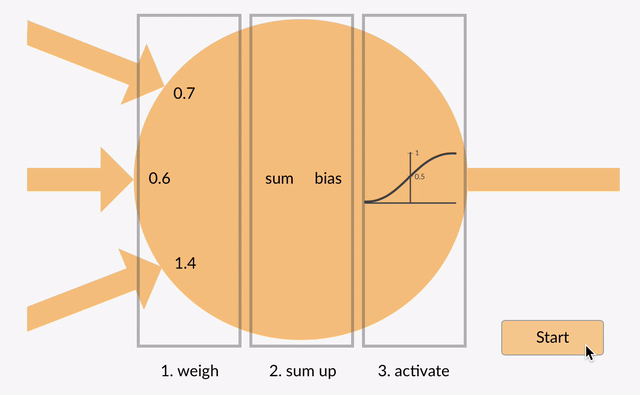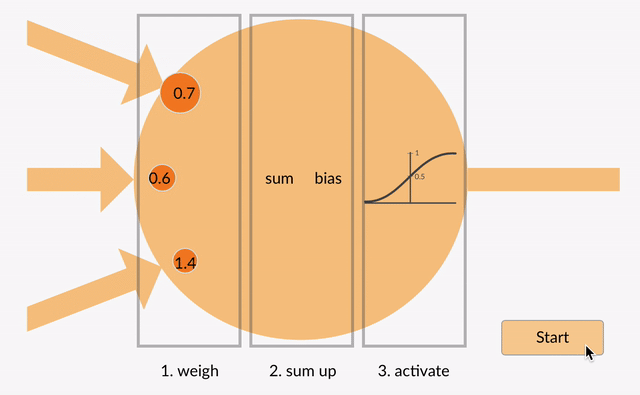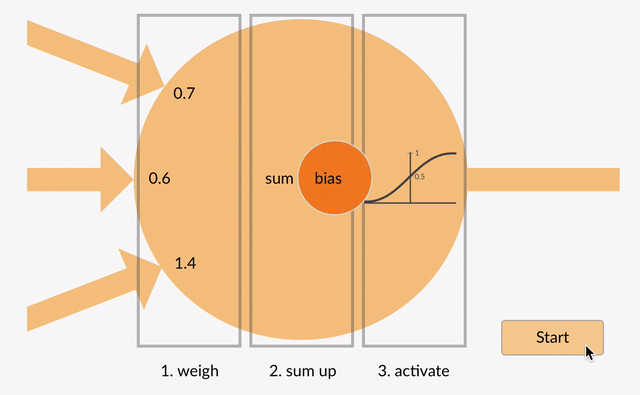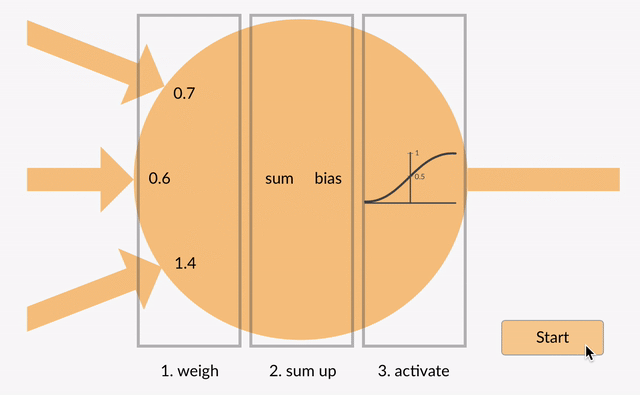
Desafio1¶
Calcule a saida do perceptron abaixo:

x0 = 2; x1 = 0; x2 = -1,24; bias = 1; w0 = 0; w1 = 2; w3 = 1; função de ativação = Heaviside
Resposta:¶
Implementação de uma rede perceptron¶
Vamos usar um framework de machine learnning chamado TensorFlow/keras para fazer esta implementação.
pip install tensorflow
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(units=1, input_shape=[1])
])
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 1) 2
=================================================================
Total params: 2 (8.00 Byte)
Trainable params: 2 (8.00 Byte)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Layers¶
O arranjo de neuronios define a quantidade de camadas ou layers que a rede neural possui na rede perceptron possui apenas uma camada. Em uma rede MLP (multlayer perceptron) possui além das camadas de entrada e saída, camadas ocultas ou hiden layers, essas redes tambem são conhecidas por redes densas ou fully-connected.

Funão de ativação¶
É basicamente uma função matematica que é responsavel por ativar ou mudar o comportamento de saída do neuronio.
Dentre as mais comuns temos:
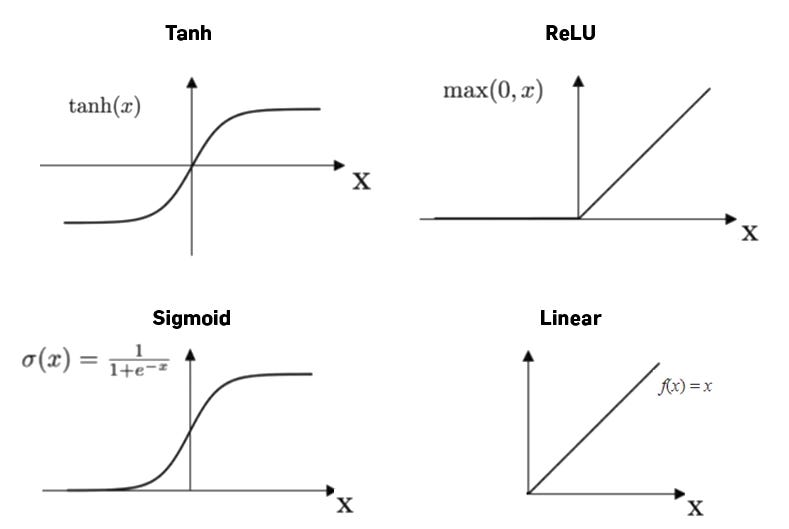
Outras funções de ativação muito utilizadas são:
- softplus
- elu
- sigmoid
- tanh
Desafio 2¶
Implemente a rede MLP abaixo usando TensorFlor/keras: função de ativação Relu
Dica: use o argumento activation='relu' em layers.Dense
## Sua resposta aqui...
Backpropagation¶
A técnica de backpropagation é fundamental para o treinamento de redes neurais, pois é através dela que os pesos são ajustados em função do erro calculado pela função de perda (Loss).
Funções de Perda (Loss Functions)¶
Mean Squared Error (MSE): Utilizado em problemas de regressão. Calcula a média dos quadrados das diferenças entre os valores previstos e os valores reais.Mean Absolute Error (MAE): Também utilizado em problemas de regressão. Calcula a média do valor absoluto das diferenças entre os valores previstos e os valores reais.Binary Cross-Entropy (BCE): Utilizado em problemas de classificação binária. Mede a diferença entre duas distribuições de probabilidade, a prevista e a real.
Otimizadores (Optimizers)¶
Os otimizadores são algoritmos que ajustam os pesos da rede neural com o objetivo de minimizar a função de perda. Alguns dos otimizadores mais comuns são:
Stochastic Gradient Descent (SGD): Um dos otimizadores mais simples e amplamente utilizados. Atualiza os pesos em pequenos passos, na direção oposta ao gradiente da função de perda.RMSprop: Adapta a taxa de aprendizado para cada parâmetro, dividindo a taxa de aprendizado por uma média móvel do quadrado dos gradientes.Adam: Combina as ideias do RMSprop e do SGD com momentum. Mantém uma média móvel tanto do gradiente quanto do quadrado do gradiente, e usa essas médias para adaptar a taxa de aprendizado para cada parâmetro.(um dos mais utilizados)Adadelta: Uma extensão do Adagrad que busca reduzir seu comportamento agressivo de diminuição da taxa de aprendizado.Adagrad: Adapta a taxa de aprendizado para cada parâmetro, escalando-os inversamente proporcionalmente à raiz quadrada da soma de todos os gradientes quadrados passados.Adamax: Uma variante do Adam baseada na norma infinita.Entre outros...


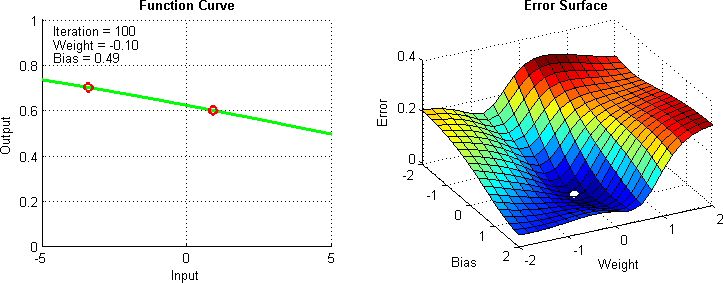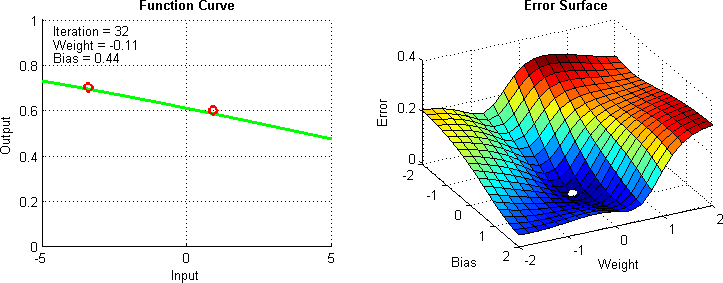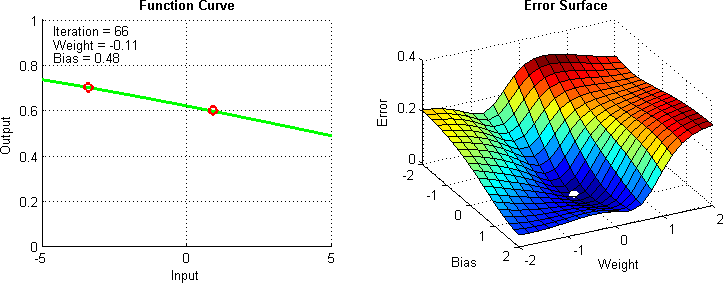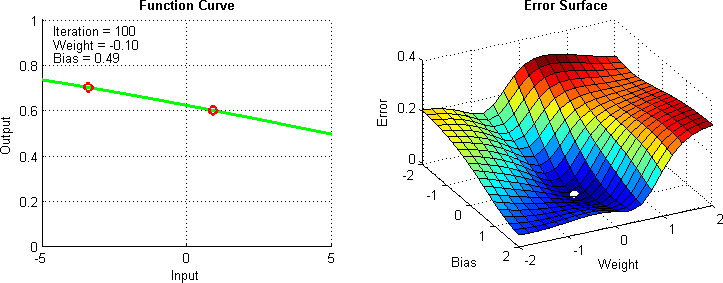

model.compile(optimizer=tf.keras.optimizers.Adam(0.1), loss = 'mse')
Pausa para carregar e preparar os dados para treinamento¶
!wget https://raw.githubusercontent.com/arnaldojr/disruptivearchitectures/master/material/aulas/IA/lab07/SalesData.csv /content
--2024-04-01 10:12:46-- https://raw.githubusercontent.com/arnaldojr/disruptivearchitectures/master/material/aulas/IA/lab07/SalesData.csv Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.108.133, 185.199.110.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 11884 (12K) [text/plain] Saving to: ‘SalesData.csv’ SalesData.csv 100%[===================>] 11.61K --.-KB/s in 0s 2024-04-01 10:12:46 (53.2 MB/s) - ‘SalesData.csv’ saved [11884/11884] /content: Scheme missing. FINISHED --2024-04-01 10:12:46-- Total wall clock time: 0.2s Downloaded: 1 files, 12K in 0s (53.2 MB/s)
import pandas as pd
import numpy as np
df = pd.read_csv('SalesData.csv')
df.info()
# Separa os dados em X e y
X_train = df['Temperature']
y_train = df['Revenue']
<class 'pandas.core.frame.DataFrame'> RangeIndex: 500 entries, 0 to 499 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Temperature 500 non-null float64 1 Revenue 500 non-null float64 dtypes: float64(2) memory usage: 7.9 KB
import seaborn as sns
sns.scatterplot(x=X_train, y=y_train);

### Tente fazer o treinamento, se der erro! faça o ajustes necessários na camada sequencial em layer.dense().
epochs_hist = model.fit(X_train, y_train, epochs=10)
Epoch 1/10 16/16 [==============================] - 1s 3ms/step - loss: 315555.9688 Epoch 2/10 16/16 [==============================] - 0s 2ms/step - loss: 273533.7812 Epoch 3/10 16/16 [==============================] - 0s 2ms/step - loss: 235616.6250 Epoch 4/10 16/16 [==============================] - 0s 3ms/step - loss: 201430.7500 Epoch 5/10 16/16 [==============================] - 0s 3ms/step - loss: 171413.8906 Epoch 6/10 16/16 [==============================] - 0s 3ms/step - loss: 144605.4844 Epoch 7/10 16/16 [==============================] - 0s 2ms/step - loss: 121690.9766 Epoch 8/10 16/16 [==============================] - 0s 3ms/step - loss: 101589.6562 Epoch 9/10 16/16 [==============================] - 0s 2ms/step - loss: 84055.3672 Epoch 10/10 16/16 [==============================] - 0s 2ms/step - loss: 69379.4141
import pandas as pd
history_df = pd.DataFrame(epochs_hist.history)
history_df['loss'].plot();

# Previsões com o modelo treinado
temp = 5
receita = model.predict([temp])
print('Previsão de Receita Usando a ANN Treinada =', receita[0][0])
1/1 [==============================] - 0s 39ms/step Previsão de Receita Usando a ANN Treinada = 136.9302
import matplotlib.pyplot as plt
plt.scatter(X_train, y_train, color = 'gray')
plt.plot(X_train, model.predict(X_train), color = 'red')
plt.ylabel('Receita [dólares]')
plt.xlabel('Temperatura [°C]')
plt.title('Receita Gerada vs. Temperatura no Ponto de Venda de Sorvetes')
16/16 [==============================] - 0s 2ms/step
Text(0.5, 1.0, 'Receita Gerada vs. Temperatura no Ponto de Venda de Sorvetes')

desafio 3:¶
O treinamento para 10 épocas ficou bom??? se não, melhore o resultado.
### seu código aqui.....
Resumo do dia¶
Até o momento fizemos o seguinte:
- Carregar e Visualizar os Dados
- Criar e Compilar o Modelo
- Treinamento
- Avaliação e Predição
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
from tensorflow.keras import layers
import tensorflow as tf
from tensorflow import keras
def carregar_e_visualizar_dados():
# Carregar os dados
#!wget https://raw.githubusercontent.com/arnaldojr/disruptivearchitectures/master/material/aulas/IA/lab07/SalesData.csv /content
df = pd.read_csv('SalesData.csv')
df.info()
# Separar os dados
X_train = df['Temperature']
y_train = df['Revenue']
# Visualizar os dados
sns.scatterplot(x=X_train, y=y_train)
plt.show()
return X_train, y_train
def criar_e_compilar_modelo():
# Criar o modelo
model = keras.Sequential([
layers.Dense(units=1, input_shape=[1])
])
# Compilar o modelo
model.compile(optimizer=tf.keras.optimizers.Adam(0.1), loss='mse')
model.summary()
return model
def treinar_modelo(model, X_train, y_train, epochs=100):
historico_epochs = model.fit(X_train, y_train, epochs=epochs)
df_historico = pd.DataFrame(historico_epochs.history)
df_historico['loss'].plot()
plt.show()
return model
def avaliar_e_prever(model, X_train, y_train):
# Visualizar as predições do modelo
plt.scatter(X_train, y_train, color='gray')
plt.plot(X_train, model.predict(X_train), color='red')
plt.ylabel('Receita [dólares]')
plt.xlabel('Temperatura [°C]')
plt.title('Receita Gerada vs. Temperatura no Ponto de Venda de Sorvetes')
plt.show()
# Fazer uma previsão
temp = 5
receita = model.predict([temp])
print('Previsão de Receita Usando a ANN Treinada =', receita)
# ---- Programa principal ----
# Carregar e visualizar os dados
X_train, y_train = carregar_e_visualizar_dados()
# Criar e compilar o modelo
model = criar_e_compilar_modelo()
# Treinar o modelo
model = treinar_modelo(model, X_train, y_train)
# Avaliar e fazer predições
avaliar_e_prever(model, X_train, y_train)
<class 'pandas.core.frame.DataFrame'> RangeIndex: 500 entries, 0 to 499 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Temperature 500 non-null float64 1 Revenue 500 non-null float64 dtypes: float64(2) memory usage: 7.9 KB
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 1) 2
=================================================================
Total params: 2 (8.00 Byte)
Trainable params: 2 (8.00 Byte)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Epoch 1/100
16/16 [==============================] - 0s 2ms/step - loss: 319039.4062
Epoch 2/100
16/16 [==============================] - 0s 2ms/step - loss: 276887.2812
Epoch 3/100
16/16 [==============================] - 0s 2ms/step - loss: 238628.3906
Epoch 4/100
16/16 [==============================] - 0s 2ms/step - loss: 204381.8906
Epoch 5/100
16/16 [==============================] - 0s 2ms/step - loss: 173926.2969
Epoch 6/100
16/16 [==============================] - 0s 2ms/step - loss: 147583.9531
Epoch 7/100
16/16 [==============================] - 0s 2ms/step - loss: 123943.3594
Epoch 8/100
16/16 [==============================] - 0s 2ms/step - loss: 103614.0625
Epoch 9/100
16/16 [==============================] - 0s 2ms/step - loss: 86137.4531
Epoch 10/100
16/16 [==============================] - 0s 2ms/step - loss: 70995.4609
Epoch 11/100
16/16 [==============================] - 0s 2ms/step - loss: 58197.1367
Epoch 12/100
16/16 [==============================] - 0s 2ms/step - loss: 47373.6836
Epoch 13/100
16/16 [==============================] - 0s 2ms/step - loss: 38204.8594
Epoch 14/100
16/16 [==============================] - 0s 2ms/step - loss: 30706.8301
Epoch 15/100
16/16 [==============================] - 0s 2ms/step - loss: 24447.9141
Epoch 16/100
16/16 [==============================] - 0s 2ms/step - loss: 19336.2246
Epoch 17/100
16/16 [==============================] - 0s 2ms/step - loss: 15294.8311
Epoch 18/100
16/16 [==============================] - 0s 2ms/step - loss: 11972.4717
Epoch 19/100
16/16 [==============================] - 0s 2ms/step - loss: 9316.7100
Epoch 20/100
16/16 [==============================] - 0s 2ms/step - loss: 7252.5850
Epoch 21/100
16/16 [==============================] - 0s 2ms/step - loss: 5654.0059
Epoch 22/100
16/16 [==============================] - 0s 2ms/step - loss: 4398.6558
Epoch 23/100
16/16 [==============================] - 0s 2ms/step - loss: 3426.6641
Epoch 24/100
16/16 [==============================] - 0s 2ms/step - loss: 2704.4099
Epoch 25/100
16/16 [==============================] - 0s 2ms/step - loss: 2150.8928
Epoch 26/100
16/16 [==============================] - 0s 2ms/step - loss: 1744.8942
Epoch 27/100
16/16 [==============================] - 0s 2ms/step - loss: 1441.0400
Epoch 28/100
16/16 [==============================] - 0s 2ms/step - loss: 1218.3285
Epoch 29/100
16/16 [==============================] - 0s 2ms/step - loss: 1058.0693
Epoch 30/100
16/16 [==============================] - 0s 3ms/step - loss: 942.4816
Epoch 31/100
16/16 [==============================] - 0s 2ms/step - loss: 861.4608
Epoch 32/100
16/16 [==============================] - 0s 2ms/step - loss: 801.4128
Epoch 33/100
16/16 [==============================] - 0s 2ms/step - loss: 760.8700
Epoch 34/100
16/16 [==============================] - 0s 2ms/step - loss: 733.4592
Epoch 35/100
16/16 [==============================] - 0s 2ms/step - loss: 712.1679
Epoch 36/100
16/16 [==============================] - 0s 2ms/step - loss: 699.5580
Epoch 37/100
16/16 [==============================] - 0s 2ms/step - loss: 690.8046
Epoch 38/100
16/16 [==============================] - 0s 2ms/step - loss: 684.1700
Epoch 39/100
16/16 [==============================] - 0s 2ms/step - loss: 680.7510
Epoch 40/100
16/16 [==============================] - 0s 2ms/step - loss: 678.0201
Epoch 41/100
16/16 [==============================] - 0s 2ms/step - loss: 675.8742
Epoch 42/100
16/16 [==============================] - 0s 2ms/step - loss: 674.7966
Epoch 43/100
16/16 [==============================] - 0s 2ms/step - loss: 673.9340
Epoch 44/100
16/16 [==============================] - 0s 2ms/step - loss: 673.5883
Epoch 45/100
16/16 [==============================] - 0s 2ms/step - loss: 673.2530
Epoch 46/100
16/16 [==============================] - 0s 2ms/step - loss: 672.8389
Epoch 47/100
16/16 [==============================] - 0s 2ms/step - loss: 672.6512
Epoch 48/100
16/16 [==============================] - 0s 2ms/step - loss: 672.6047
Epoch 49/100
16/16 [==============================] - 0s 2ms/step - loss: 672.3368
Epoch 50/100
16/16 [==============================] - 0s 2ms/step - loss: 672.2287
Epoch 51/100
16/16 [==============================] - 0s 2ms/step - loss: 672.0671
Epoch 52/100
16/16 [==============================] - 0s 2ms/step - loss: 672.0101
Epoch 53/100
16/16 [==============================] - 0s 2ms/step - loss: 671.8309
Epoch 54/100
16/16 [==============================] - 0s 2ms/step - loss: 671.6974
Epoch 55/100
16/16 [==============================] - 0s 3ms/step - loss: 671.6188
Epoch 56/100
16/16 [==============================] - 0s 2ms/step - loss: 671.5398
Epoch 57/100
16/16 [==============================] - 0s 2ms/step - loss: 671.3561
Epoch 58/100
16/16 [==============================] - 0s 2ms/step - loss: 671.3818
Epoch 59/100
16/16 [==============================] - 0s 2ms/step - loss: 671.1469
Epoch 60/100
16/16 [==============================] - 0s 2ms/step - loss: 671.0237
Epoch 61/100
16/16 [==============================] - 0s 2ms/step - loss: 670.8895
Epoch 62/100
16/16 [==============================] - 0s 2ms/step - loss: 670.7467
Epoch 63/100
16/16 [==============================] - 0s 2ms/step - loss: 670.6893
Epoch 64/100
16/16 [==============================] - 0s 2ms/step - loss: 670.5098
Epoch 65/100
16/16 [==============================] - 0s 2ms/step - loss: 670.4712
Epoch 66/100
16/16 [==============================] - 0s 3ms/step - loss: 670.2680
Epoch 67/100
16/16 [==============================] - 0s 3ms/step - loss: 670.3395
Epoch 68/100
16/16 [==============================] - 0s 2ms/step - loss: 670.0258
Epoch 69/100
16/16 [==============================] - 0s 2ms/step - loss: 670.1964
Epoch 70/100
16/16 [==============================] - 0s 2ms/step - loss: 669.7410
Epoch 71/100
16/16 [==============================] - 0s 2ms/step - loss: 669.5929
Epoch 72/100
16/16 [==============================] - 0s 2ms/step - loss: 669.4639
Epoch 73/100
16/16 [==============================] - 0s 3ms/step - loss: 669.3311
Epoch 74/100
16/16 [==============================] - 0s 2ms/step - loss: 669.4010
Epoch 75/100
16/16 [==============================] - 0s 2ms/step - loss: 669.0681
Epoch 76/100
16/16 [==============================] - 0s 2ms/step - loss: 669.0442
Epoch 77/100
16/16 [==============================] - 0s 2ms/step - loss: 668.7401
Epoch 78/100
16/16 [==============================] - 0s 2ms/step - loss: 668.9483
Epoch 79/100
16/16 [==============================] - 0s 2ms/step - loss: 668.5505
Epoch 80/100
16/16 [==============================] - 0s 2ms/step - loss: 668.4393
Epoch 81/100
16/16 [==============================] - 0s 2ms/step - loss: 668.2285
Epoch 82/100
16/16 [==============================] - 0s 2ms/step - loss: 668.0378
Epoch 83/100
16/16 [==============================] - 0s 2ms/step - loss: 667.9488
Epoch 84/100
16/16 [==============================] - 0s 2ms/step - loss: 667.7075
Epoch 85/100
16/16 [==============================] - 0s 2ms/step - loss: 667.6132
Epoch 86/100
16/16 [==============================] - 0s 2ms/step - loss: 667.4966
Epoch 87/100
16/16 [==============================] - 0s 2ms/step - loss: 667.4224
Epoch 88/100
16/16 [==============================] - 0s 2ms/step - loss: 667.1114
Epoch 89/100
16/16 [==============================] - 0s 2ms/step - loss: 667.0513
Epoch 90/100
16/16 [==============================] - 0s 2ms/step - loss: 667.2527
Epoch 91/100
16/16 [==============================] - 0s 2ms/step - loss: 666.6097
Epoch 92/100
16/16 [==============================] - 0s 2ms/step - loss: 666.5334
Epoch 93/100
16/16 [==============================] - 0s 2ms/step - loss: 666.3892
Epoch 94/100
16/16 [==============================] - 0s 2ms/step - loss: 666.1669
Epoch 95/100
16/16 [==============================] - 0s 2ms/step - loss: 666.0068
Epoch 96/100
16/16 [==============================] - 0s 2ms/step - loss: 665.8843
Epoch 97/100
16/16 [==============================] - 0s 2ms/step - loss: 665.7877
Epoch 98/100
16/16 [==============================] - 0s 2ms/step - loss: 665.5769
Epoch 99/100
16/16 [==============================] - 0s 2ms/step - loss: 665.4597
Epoch 100/100
16/16 [==============================] - 0s 2ms/step - loss: 665.3188

16/16 [==============================] - 0s 2ms/step
1/1 [==============================] - 0s 65ms/step Previsão de Receita Usando a ANN Treinada = [[136.9302]]
Desafio 4: Implementação end-to-end MLP¶
Realize o treinamento de uma rede MLP para o dataset Fashion MNIST. Um guia passo a passo pode ser encontrado no link https://www.tensorflow.org/tutorials/keras/classification.
### Seu código aqui.....