Validacaocruzada
![]()
Validação Cruzada¶
Objetivos¶
- Entender e praticar validação cruzada: kfold.
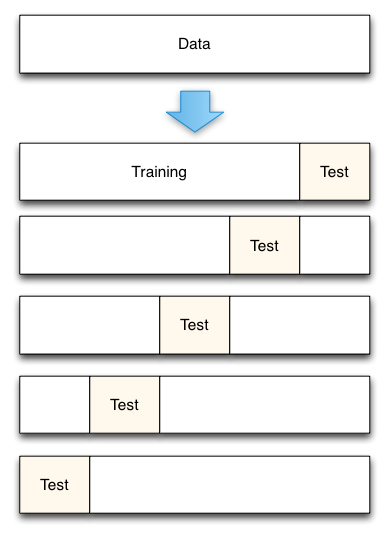
A técnica de validação cruzada consiste em dividir em partes pequenas (fold) a base de dados e realizar diversos treinamentos e validações com partes diferente de treinamento e teste, ao final é feita a média e o desvio padrão do aprendizado.
Prós:
- Normalmente aumenta a performance do modelo.
- Reduz aleatoriedade, reduz viez.
Contra:
- Mais processamento computacional.
Dicas:
- A escolha do
knumero de folds é determinada tipicamente como sendo 5 ou 10.
Diagrama do kfold¶
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
# importa o dataset iris
iris = load_iris()
# separa os dados em atributos (x) e alvo (y)
X = iris.data
y = iris.target
# divide os dados em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
# treina o modelo com knn=15
knn = KNeighborsClassifier(n_neighbors=15)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
# resultado da acuracia
metrics.accuracy_score(y_test, y_pred)
print("Acuracia: ", metrics.accuracy_score(y_test, y_pred))
Acuracia: 0.9
Melhorando o modelo¶
Até aqui, sem novidades! Mas... como ficaria o resultado se os grupos de teste e treino fossem alterados? vamos descobrir usando o kfold e crossvalidation.
from sklearn.model_selection import KFold
crossvalidation = KFold(n_splits=10,shuffle=True, random_state=7)
knn = KNeighborsClassifier(n_neighbors=5)
from sklearn.model_selection import cross_val_score
scores = cross_val_score(knn, X, y, cv=crossvalidation, scoring='accuracy')
print("Array do kfold com os resultados: ",scores)
Array do kfold com os resultados: [0.86666667 0.86666667 1. 1. 1. 1. 1. 0.93333333 0.93333333 0.93333333]
print("Acuracia média com kfold: ",scores.mean())
Acuracia média com kfold: 0.9533333333333334
Desafio¶
Pergunta: O Resultado foi praticamente o mesmo, por que?
## Sua resposta aqui....
Bonus: Outras técnicas de avaliação de modelo¶
StratifiedKFold= Lida melhor com dados desbalanceados, ou seja, possui uma diferça grande entre as frequencias das classes, pois tentar manter a mesma proporção em todos os folds.ShuffleSplit= Gera folds aleatorios de treino e teste a cada iteração. Um cuidado, pode ser que entre uma iteração e outra os mesmos dados sejam selecionados