Regressao
![]()
Objetivos¶
- Apresentar o conceito de Regressão
- Apresentar e utilizar algoritmo de Regressão linear
- Apresentar e utilizar Regressão Polinomial
- Apresentar e discutir a matriz de correlação
- Apresentar uma intuição sobre métricas de avaliação (MSE, RMSE e $ R² $ )
Começando¶
Sabemos que dentro de aprendizado supervisionado vamos trabalhar com dois tipos de problemas:
- Classificação - (Já conhecemos o KNN)
- Regressão - (Objetivo de hoje)
Uma intuição sobre problemas que envolvem cada um deles:¶
Classificação --> Resultados discretos (categóricos).
Regressão --> Resultados numéricos e contínuos.Regressão linear¶
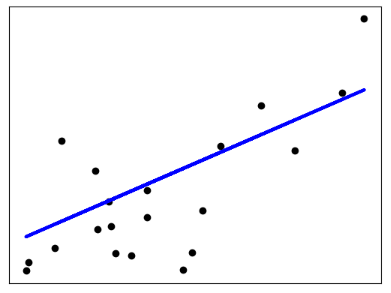
É uma técnica que consiste em representar um conjunto de dados por meio de uma reta.
Na matemática aprendemos que a equação de uma reta é:$$ Y = A + BX \\ $$ A e B são constantes que determinam a posição e inclinação da reta. Para cada valor de X temos um Y associado.
Em machine learning aprendemos que uma Regressão linear é:$$ Y_{predito} = \beta_o + \beta_1X \\ $$
$ \beta_o $ e $ \beta_1 $ são parâmetros que determinam o peso e bias da rede. Para cada entrada $ X $ temos um $ Y_{predito} $ aproximado predito.

Essa ideia se estende para mais de um parâmetro independente, mas nesse caso não estamos associando a uma reta e sim a um plano ou hiperplano:
$$ Y_{predito} = \beta_o + \beta_1X_1 + \beta_2X_2 + ... + \beta_nX_n\\ $$


Em outras palavras, modelos de regressão linear são intuitivos, fáceis de interpretar e se ajustam aos dados razoavelmente bem em muitos problemas.
Bora lá!!¶
Vamos juntos realizar um projeto, do começo ao fim, usando regressão.
Desafio 1¶
Do ponto de vista de machine learning, que problema é esse:
Aprendizado supervisionado, não-supervisionado ou aprendizado por reforço?R:
Classificação, regressão ou clusterização?R:
# Inicializção das bibliotecas
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
O scikit-learn possui diversos dataset em seu banco de dados, um deles é o dataset que vamos utilizar hoje.
faça o import direto usando sklearn.datasets
caso queira, você pode fazer o downlod do dataset direto do site e importar em seu projeto.
from sklearn.datasets import fetch_california_housing
california_dataset = fetch_california_housing()
#para conhecer o que foi importado do dataset
california_dataset.keys()
dict_keys(['data', 'target', 'frame', 'target_names', 'feature_names', 'DESCR'])
# vamos carregar no pandas apenas data com os dados e "feature_names" com os nomes dos atributos
df = pd.DataFrame(california_dataset.data, columns=california_dataset.feature_names)
df.head()
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 |
#vamos adicionar mais uma coluna ao nosso dataframe com o target (alvo que vamos fazer a predição)
df['MEDV'] = california_dataset.target
Pronto!! agora o nosso dataset está completamente carregado e podemos começar a análise de dados.
df.head()
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | MEDV | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 | 4.526 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 | 3.585 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 | 3.521 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 | 3.413 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 | 3.422 |
O que significa cada coluna?¶
| Coluna | Significado | Exemplo |
|---|---|---|
| MedInc | Renda média da região | 8.32 (dezenas de milhares) |
| HouseAge | Idade média das casas | 41.0 anos |
| AveRooms | Número médio de quartos | 6.98 |
| AveBedrms | Quartos de dormir médios | 1.02 |
| Population | População da área | 322 pessoas |
| AveOccup | Ocupação média | 2.55 pessoas/casa |
| Latitude | Coordenada geográfica | 37.88 |
| Longitude | Coordenada geográfica | -122.23 |
| MEDV | Preço médio das casas | 4.526 (centenas de milhares) |
Importante: O preço está em centenas de milhares. 4.526 = $452,600
Desafio 2¶
Use os metodos info() e describe() para exibir as informações do dataframe e responda:
Existe dados faltantes?
Qual o tamanho do dataset, quantas linhas e quantas colunas?
# Mostra informações sobre o dataframe em si
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 20640 entries, 0 to 20639 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 MedInc 20640 non-null float64 1 HouseAge 20640 non-null float64 2 AveRooms 20640 non-null float64 3 AveBedrms 20640 non-null float64 4 Population 20640 non-null float64 5 AveOccup 20640 non-null float64 6 Latitude 20640 non-null float64 7 Longitude 20640 non-null float64 8 MEDV 20640 non-null float64 dtypes: float64(9) memory usage: 1.4 MB
df.describe()
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | MEDV | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | 3.870671 | 28.639486 | 5.429000 | 1.096675 | 1425.476744 | 3.070655 | 35.631861 | -119.569704 | 2.068558 |
| std | 1.899822 | 12.585558 | 2.474173 | 0.473911 | 1132.462122 | 10.386050 | 2.135952 | 2.003532 | 1.153956 |
| min | 0.499900 | 1.000000 | 0.846154 | 0.333333 | 3.000000 | 0.692308 | 32.540000 | -124.350000 | 0.149990 |
| 25% | 2.563400 | 18.000000 | 4.440716 | 1.006079 | 787.000000 | 2.429741 | 33.930000 | -121.800000 | 1.196000 |
| 50% | 3.534800 | 29.000000 | 5.229129 | 1.048780 | 1166.000000 | 2.818116 | 34.260000 | -118.490000 | 1.797000 |
| 75% | 4.743250 | 37.000000 | 6.052381 | 1.099526 | 1725.000000 | 3.282261 | 37.710000 | -118.010000 | 2.647250 |
| max | 15.000100 | 52.000000 | 141.909091 | 34.066667 | 35682.000000 | 1243.333333 | 41.950000 | -114.310000 | 5.000010 |
Desafio 3¶
Aplique os métodos que achar conveniente (vimos algumas opções na última aula) para visualizar os dados de forma gráfica.
## Sua resposta e seus gráficos para análisar..
# Vamos visualizar a relação entre as variáveis
# Longitude e Latitude em relação ao preço médio das casas
df.plot(kind="scatter", x="Longitude",y="Latitude", c="MEDV", cmap="jet", colorbar=True, legend=True, sharex=False, figsize=(10,7), s=df['Population']/100, label="population", alpha=0.7)
plt.show()

#Vamos explorar um pouco uma matrix de correlação
import seaborn as sns
correlation_matrix = df.corr().round(2)
fig, ax = plt.subplots(figsize=(10,10))
sns.heatmap(data=correlation_matrix, annot=True, linewidths=.5, ax=ax)
<Axes: >

PARE!!!¶
A análise feita no desafio 2 e 3 é uma das etapas mais importantes. Caso você tenha pulado essa etapa, volte e faça suas análises.
Com essa etapa concluída, vamos criar um sub-dataset com os atributos que serão utilizados.
# Vamos treinar nosso modelo com 2 dois atributos independentes
# para predizer o valor de saida
# X = df[['MedInc', 'HouseAge']] ### teste com duas entradas
X = df[['MedInc']] ### teste com uma entrada
#X = df.drop(['MEDV'], axis=1) ### teste com todas as entradas
Y = df['MEDV']
print(f"Formato das tabelas de dados {X.shape} e saidas {Y.shape}")
Formato das tabelas de dados (20640, 1) e saidas (20640,)
Dividindo os dados em conjunto de treinamento e de testes¶
Dividir nosso dataset em dois conjuntos de dados.
Treinamento - Representa 80% das amostras do conjunto de dados original,
Teste - com 20% das amostrasVamos escolher aleatoriamente algumas amostras do conjunto original. Isto pode ser feito com Scikit-Learn usando a função train_test_split()
scikit-learn Caso ainda não tenha instalado, no terminal digite:
- pip install scikit-learn
# Separamos 20% para o teste
from sklearn.model_selection import train_test_split
X_treino, X_teste, Y_treino, Y_teste = train_test_split(X, Y, test_size=0.2)
print(X_treino.shape)
print(X_teste.shape)
print(Y_treino.shape)
print(Y_teste.shape)
(16512, 1) (4128, 1) (16512,) (4128,)
Treinando Nosso Primeiro Modelo¶
Treinar um modelo no python é simples se usar o Scikit-Learn.
Treinar um modelo no Scikit-Learn é simples: basta criar o regressor, e chamar o método fit().
Uma observação sobre a sintaxe dos classificadores do scikit-learn
O método
fit(X,Y)recebe uma matriz ou dataframe X onde cada linha é uma amostra de aprendizado, e um array Y contendo as saídas esperadas do classificador, seja na forma de texto ou de inteirosO método
predict(X)recebe uma matriz ou dataframe X onde cada linha é uma amostra de teste, retornando um array de classes
# Importa a biblioteca
from sklearn.linear_model import LinearRegression
# Cria o modelo de regressão
lin_model = LinearRegression()
# Cria o modelo de machine learning
lin_model.fit(X_treino, Y_treino)
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| fit_intercept | True | |
| copy_X | True | |
| tol | 1e-06 | |
| n_jobs | None | |
| positive | False |
Pronto!! bora testar se esta funcionando....
# Para obter as previsões, basta chamar o método predict()
y_teste_predito = lin_model.predict(X_teste)
print("Predição usando regressão, retorna valores continuos: {}".format(y_teste_predito))
Predição usando regressão, retorna valores continuos: [1.22201031 1.20622349 0.8628707 ... 1.27463304 1.3798785 1.49131239]
# vamos avaliar os parametros do nosso modelo
print('(A) Intercepto: ', lin_model.intercept_)
print('(B) Inclinação: ', lin_model.coef_)
print('(C) Equação: Y = {} + {} * X'.format(lin_model.intercept_, lin_model.coef_[0]))
(A) Intercepto: 0.432669361569749 (B) Inclinação: [0.42098184] (C) Equação: Y = 0.432669361569749 + 0.4209818390411239 * X
plt.scatter(Y_teste,y_teste_predito, alpha=0.2)
plt.xlabel('Valor Real')
plt.ylabel('Valor Predito')
Text(0, 0.5, 'Valor Predito')

Avaliando o modelo treinado¶
Vamos colocar alguns valores e ver a predição do classificador.
from sklearn.metrics import r2_score, mean_squared_error,mean_absolute_error
import numpy as np
print("Soma dos Erros ao Quadrado (SSE): %2.f " % np.sum((y_teste_predito - Y_teste)**2))
print("Erro Quadrático Médio (MSE): %.2f" % mean_squared_error(Y_teste, y_teste_predito))
print("Erro Médio Absoluto (MAE): %.2f" % mean_absolute_error(Y_teste, y_teste_predito))
print ("Raiz do Erro Quadrático Médio (RMSE): %.2f " % np.sqrt(mean_squared_error(Y_teste, y_teste_predito)))
print("R2-score: %.2f" % r2_score(Y_teste, y_teste_predito))
Soma dos Erros ao Quadrado (SSE): 3014 Erro Quadrático Médio (MSE): 0.73 Erro Médio Absoluto (MAE): 0.63 Raiz do Erro Quadrático Médio (RMSE): 0.85 R2-score: 0.45
Algoritmos de ML para regressão¶
Sugestão de alguns algoritmos de ML para problemas de regressão:
| Nome | Vantagem | Desvantagem | Exemplo sklearn |
|---|---|---|---|
| Regressão Linear | Fácil de entender e implementar | Pode não ser adequado para problemas mais complexos | from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X, y) prediction = model.predict([X_teste]) |
| Árvores de decisão | Fácil de entender e visualizar | Pode levar a overfitting se a árvore for muito grande | from sklearn.tree import DecisionTreeRegressor model = DecisionTreeRegressor() model.fit(X, y) prediction = model.predict([X_teste]) |
| Random Forest | Mais robusto e geralmente mais preciso do que uma única árvore de decisão | Pode ser mais lento e mais difícil de ajustar | from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(n_estimators=100) model.fit(X, y) prediction = model.predict([X_teste]) |
| Support Vector Regression (SVR) | Lida bem com dados multidimensionais e não lineares | Pode ser difícil de escolher o kernel correto e ajustar os hiperparâmetros | from sklearn.svm import SVR model = SVR(kernel='rbf') model.fit(X, y) prediction = model.predict([X_teste]) |
| Gradient Boosting | Preciso e lida bem com dados multidimensionais e não lineares | Pode ser mais lento e mais difícil de ajustar | from sklearn.ensemble import GradientBoostingRegressor model = GradientBoostingRegressor(n_estimators=100) model.fit(X, y) prediction = model.predict([X_teste]) |
Exercício 1: Experimentar outras variáveis¶
- Tente usar apenas
HouseAgepara predizer preço - Compare o R² com o modelo que usa
MedInc - Qual variável sozinha é melhor preditora?
Exercício 2: Modelo com todas as variáveis¶
- Crie um modelo usando todas as 8 variáveis
- Compare com o modelo de 4 variáveis
- Houve melhoria significativa?
## implemente sua sua solução....
# testa o random forest
from sklearn.ensemble import GradientBoostingRegressor
model = GradientBoostingRegressor(n_estimators=100)
model.fit(X_treino, Y_treino)
y_teste_predito_gb = model.predict(X_teste)
y_teste_predito_rf = model.predict(X_teste)
print("Soma dos Erros ao Quadrado (SSE): %2.f " % np.sum((y_teste_predito_rf - Y_teste)**2))
print("Erro Quadrático Médio (MSE): %.2f" % mean_squared_error(Y_teste, y_teste_predito_rf))
print("Erro Médio Absoluto (MAE): %.2f" % mean_absolute_error(Y_teste, y_teste_predito_rf))
print ("Raiz do Erro Quadrático Médio (RMSE): %.2f " % np.sqrt(mean_squared_error(Y_teste, y_teste_predito_rf)))
print("R2-score: %.2f" % r2_score(Y_teste, y_teste_predito_rf))
Soma dos Erros ao Quadrado (SSE): 2914 Erro Quadrático Médio (MSE): 0.71 Erro Médio Absoluto (MAE): 0.62 Raiz do Erro Quadrático Médio (RMSE): 0.84 R2-score: 0.47
## implemente sua sua solução....
## implemente sua sua solução....
## implemente sua sua solução....
## implemente sua sua solução....