Lab01 - DataFrame
![]()
Objetivos¶
- Apresentar e utilizar o pacote pandas
- Como carregar uma base dados
- Como visualizar os dados
- Intuição de análise exploratória de dados
Introdução a análise de dados usando Pandas¶
Vamos começar pelo começo! Vamos escolher um dataset (conjunto de dados) para analisar.
Vamos utilizar um pacote do python capaz de trabalhar com tabelas de dados chamada pandas, para essas tabelas chamamos de dataframe.
Veja mais em: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
Para instalar
- pandas:
pip install pandas
LEIA A DOCUMENTAÇÃO: https://pandas.pydata.org/docs/index.html
import pandas as pd
Hello World! do mundo dos dados¶
Conjunto de dados Dataset¶
Para trabalhar com análise de dados precisamos de.... DADOS.
Podemos escolher qualquer base de dados disponivel na internet, ou até mesmo criar nosso proprio dataset.
Vamos simplificar essa etapa e começar analisando uma base pequena e muito famosa chamada iris que esta disponivel em:
ref: https://archive.ics.uci.edu/ml/datasets/Iris
Conheça outros datasets: https://archive.ics.uci.edu/ml/datasets.php
# Caminho do arquivo
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Lê e carrega o arquivo para a memória
df = pd.read_csv(url)
Conhecendo os dados¶
Essa etapa é muito importante, CONHECER OS DADOS!
Quanto mais você conhece a base de DADOS maior a possibilidade de extrair INFORMAÇÕES úteis para tomada de decisão.
df.head()
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa | |
|---|---|---|---|---|---|
| 0 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 2 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 3 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| 4 | 5.4 | 3.9 | 1.7 | 0.4 | Iris-setosa |
Note que a primeira linha não contem os nomes das colunas ou atributos(variaveis) e sim, dados (valores).
Dependendo da base dados utilizada e como você carrega no pandas, os dados da primeira linha são importados como atributos.
Vamos adicionar um cabeçario ao nosso dataframe. Mas o que podemos adicionar???
Vamos dar uma olhada no repositório oficial onde dadas informações sobre o dataset e é dito que as variaveis são:
Attribute Information:
1. sepal length in cm
2. sepal width in cm
3. petal length in cm
4. petal width in cm
5. class:
-- Iris Setosa
-- Iris Versicolour
-- Iris Virginica
# Define o nome das colunas
header = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
# Lê e carrega o arquivo para a memória
df = pd.read_csv(url, header=None, names=header)
# Retorna um trecho com as 5 primeiras linhas do dataframe
df.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
análisando o dataset¶
Agora que já carregamos o dataset corretamente, vamos começar a analisa-lo. o método info() é um bom ponto de partida para isso.
# Mostra informações sobre o dataframe em si
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal_length 150 non-null float64 1 sepal_width 150 non-null float64 2 petal_length 150 non-null float64 3 petal_width 150 non-null float64 4 species 150 non-null object dtypes: float64(4), object(1) memory usage: 6.0+ KB
# exibe o shape (dimensoẽs) do dataframe
df.shape
(150, 5)
Desafio 1¶
Analisando as informações do dataset iris, responda:
Quantos dados existem nesse dataset?
Qual a quantidade de atributos?
Existe valores faltantes?
De que tipo são os dados (dtype)?
## Suas respostas....
Análisando os dados mais a fundo¶
São 150 exemplares de flor de íris, pertencentes a três espécies diferentes: setosa, versicolor e virginica, sendo 50 amostras de cada espécie.
Os atributos de largura e comprimento de sépala e largura e comprimento de pétala de cada flor fooram medidos manualmente.

Resumo estatístico¶
O método describe() gera um resumo estatístico dos dados contidos em um DataFrame ou Series.
Retorna estatísticas descritivas como média, desvio padrão, valor mínimo, quartis e valor máximo para as colunas numéricas do DataFrame
df.describe()
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
Note que o método describe() não exibe a coluna species, pois se trata de uma coluna não-numérica.
Apenas as colunas numéricas estão presentes, o atributo species indica rótulos - trata-se de dados categóricos.
# retorna a quantiade de classes da coluna
df.species.unique()
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)
Desafio 2¶
Analisando as informações obtidas com o metodo describe(), responda:
Qual é a média (mean) do comprimento das sépalas (sepal length) no conjunto de dados Iris?
Qual é o desvio padrão (std) da largura das pétalas (petal width)?
Interprete o valor do quartil 25% (25%) para o comprimento das pétalas (petal length). O que ele representa?
Compare as médias do comprimento das sépalas entre as diferentes espécies de Iris. Qual espécie tem o maior valor médio?
Com base nos resultados do describe(), qual espécie parece ter a maior variação no tamanho das pétalas?
Se um novo registro de Iris tem um comprimento de sépala de 7.5 cm, como esse valor se compara com a distribuição do comprimento das sépalas no conjunto de dados? Ele é considerado um valor alto, baixo ou dentro da média?
## Suas respostas....
Agrupando dados¶
O método groupby é usada para agrupar dados com base em valores específicos de uma ou mais colunas.
Permite realizar operações em grupos de dados e é muito útil e versatil para análise e agregação de dado.
# agrupamento por média
df.groupby('species').mean()
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| species | ||||
| Iris-setosa | 5.006 | 3.418 | 1.464 | 0.244 |
| Iris-versicolor | 5.936 | 2.770 | 4.260 | 1.326 |
| Iris-virginica | 6.588 | 2.974 | 5.552 | 2.026 |
# Quantidade de cada categoria
df.groupby('species').size()
species Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 dtype: int64
Limpeza de Dados¶
Base de dados do mundo real podem conter diversos problemas, é muito comum o lidar com valores faltantes em um dataset.
Como exemplo, vamos usar o conjunto de dados Iris, mas introduzimos algumas 'imperfeições' para fins de demonstração.
Para introduzir valores faltantes, podemos usar o seguinte código:
## Gera dados faltante no dataset
for col in df_iris.columns[:-1]:
df_iris.loc[np.random.choice(df_iris.index, 5), col] = np.nan
import numpy as np
# cópia de df
df_iris = df
# Gera dados faltante no dataset
for col in df_iris.columns[:-1]:
df_iris.loc[np.random.choice(df_iris.index, 5), col] = np.nan
df_iris.info()
<class 'pandas.core.frame.DataFrame'> Int64Index: 131 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal_length 121 non-null float64 1 sepal_width 121 non-null float64 2 petal_length 122 non-null float64 3 petal_width 121 non-null float64 4 species 131 non-null object dtypes: float64(4), object(1) memory usage: 10.2+ KB
# Verifica os valores ausentes
df_iris.isnull().sum()
sepal_length 10 sepal_width 10 petal_length 9 petal_width 10 species 0 dtype: int64
Excluindo linhas¶
Podemos simplismente excluir as linhas ou colunas que contenham dados faltantes, basta usar a função dropna pandas, utilizando como parâmetros o axis = 1 para dizer que queremos deletar a coluna ou axis = 0 para linha e inplace = True para aplicarmos no dataset e não criarmos uma cópia deste:
axis=0--> exclui linhaaxis=1--> exclui coluna
Pense bemmmm!!!! A decisão por qual vai excluir depende do problema que você está atacando...
df_iris.dropna(axis=0, inplace=True)
Preenchimento com valores¶
Você pode preencher os valores faltantes com médias, medianas, modas ou outros valores relevantes.
Isso ajuda a manter o tamanho do conjunto de dados, mas pode introduzir viés nos resultados.
Pense bemmmm!!!! A decisão por qual valor preencher depende do problema que você está atacando...
# Tratamento de valores faltantes: imputação média
for col in df_iris.columns[:-1]: # a coluna de especie não entra
mean_val = df_iris[col].mean()
df_iris[col].fillna(mean_val, inplace=True)
df_iris.info()
<class 'pandas.core.frame.DataFrame'> Int64Index: 131 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal_length 131 non-null float64 1 sepal_width 131 non-null float64 2 petal_length 131 non-null float64 3 petal_width 131 non-null float64 4 species 131 non-null object dtypes: float64(4), object(1) memory usage: 10.2+ KB
Analisando informações em gráficos¶
Uma análise gráfica pode ajudar a compreeder melhor os dados que estamos trabalhando....
Vamos explorar diferentes tipos de visualizações que podem nos ajudar a entender melhor nossos dados.
Vamos usar o matplotlib e o seaborn para nos ajudar.
Se precisar instalar:
- pip install matplotlib seaborn
import matplotlib.pyplot as plt
import seaborn as sns
# Gráfico de linha para a média do comprimento da sépala de cada espécie
grouped = df_iris.groupby('species')['sepal_length'].mean()
grouped.plot(kind='line', marker='o')
plt.title('Média do Comprimento da Sépala por Espécie')
plt.ylabel('Comprimento da Sépala (cm)')
plt.grid(True)
plt.show()

# Gráfico de Barras
species_count = df['species'].value_counts()
species_count.plot(kind='bar')
plt.title('Contagem de Espécies')
plt.xlabel('Espécie')
plt.ylabel('Contagem')
plt.show()

histograma¶
Um histograma é um tipo de gráfico usado para representar a distribuição de frequências de um conjunto de dados.
Ele é composto por barras, onde cada barra representa um intervalo de valores (também chamado de "bin").
A altura de cada barra indica a frequência (ou quantidade) de dados que caem dentro desse intervalo.
# Lembra de histograma, que exibe uma gráfico de frequência.
df.hist(bins=100, figsize=(15, 15))
plt.show()

# Histograma apenas de um atributo
plt.hist(df['sepal_length'], bins=100)
plt.title('Histograma de Sepal Length')
plt.xlabel('Sepal Length')
plt.ylabel('Contagem')
plt.show()

Desafio 3¶
Com base nos histogramas, responda:
Crie um histograma para o largura das sépalas (sepal width) para visualizar a distribuição dessa característica no conjunto de dados.
Crie histogramas para diferentes características (como largura das sépalas, largura das pétalas, etc.) e compare a variabilidade entre elas. Observe quais características têm maior dispersão.
Explore utilizar diferentes números de bins (intervalos) no histograma e observe como isso afeta a visualização da distribuição. Qual o número adequado de bins para a interpretação dos dados?
### Suas respostas....
Boxplot¶
Um boxplot, também conhecido como diagrama de caixa, é um gráfico usado para representar a distribuição de um conjunto de dados através de cinco medidas resumidas: mínimo, primeiro quartil (Q1), mediana (Q2), terceiro quartil (Q3) e máximo.
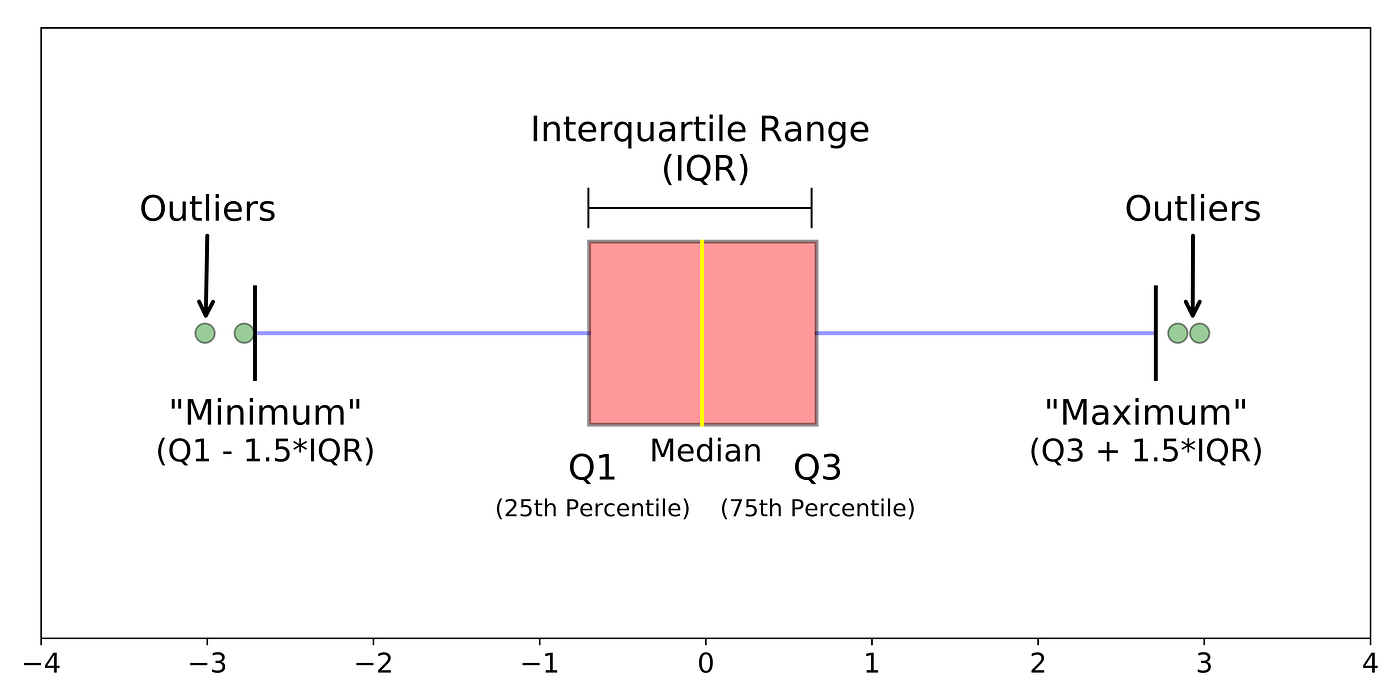
# box plot de todos
df.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False, figsize=(15, 15))
plt.show()

### boxplot para uma especie especifica
# Filtrar os dados para a espécie Iris-virginica
virginica = df[df['species'] == 'Iris-virginica']
virginica.plot(kind='box', y='petal_length', figsize=(6, 6))
plt.title('Boxplot do Comprimento das Pétalas de Iris-virginica')
plt.ylabel('Comprimento das Pétalas (cm)')
plt.show()
Desafio 4¶
Com base nos boxplot, responda:
Qual é o valor do terceiro quartil (Q3) para o comprimento das pétalas (petal length) da espécie Iris-setosa?
Compare o primeiro quartil (Q1) da largura das sépalas (sepal width) entre as três espécies de Iris. Qual espécie tem o menor Q1?
Identifique se há outliers no boxplot do comprimento das sépalas (sepal length) para a espécie Iris-versicolor. Se sim, especifique o número aproximado de outliers.
Explique como os outliers são determinados em um boxplot.
Compare os boxplots do comprimento das pétalas (petal length) e da largura das pétalas (petal width) para a espécie Iris-versicolor. Qual característica tem maior variabilidade?
Observando o boxplot da largura das sépalas (sepal width) para a espécie Iris-setosa, a distribuição dos dados é simétrica ou assimétrica? Como você pode dizer isso a partir do boxplot?
Compare a simetria dos boxplots do comprimento das sépalas (sepal length) entre as três espécies de Iris. Qual espécie apresenta a distribuição mais simétrica?
### Suas respostas.......
Scatter¶
Um scatter plot, ou gráfico de dispersão, é uma representação gráfica que utiliza pontos para mostrar a relação entre duas variáveis numéricas.
Cada ponto no gráfico corresponde a um par de valores das duas variáveis. Scatter plots são úteis para identificar padrões, tendências, correlações ou possíveis associações entre as variáveis.
# Grafico de dispersão
plt.scatter(df_iris['sepal_length'], df_iris['petal_length'])
plt.title('Sepal Length vs Petal Length')
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Petal Length (cm)')
plt.show()

# Os mesmos dados mas agora cada classe de uma cor diferente
colors = {'Iris-setosa':'red', 'Iris-versicolor':'blue', 'Iris-virginica':'green'}
plt.scatter(df['sepal_length'], df['petal_length'], c=df['species'].map(colors), label=colors)
plt.title('Sepal Length vs Petal Length')
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Petal Length (cm)')
plt.legend(handles=[plt.Line2D([0], [0], marker='o', color='w', markerfacecolor=color, markersize=10) for color in colors.values()], labels=colors.keys())
plt.show()

# scatter plot matrix
# tudo junto e misturado
from pandas.plotting import scatter_matrix
scatter_matrix(df,figsize=(15, 15))
plt.show()

Vamos utilizar o seaborn para visualizar gráficos mais bonitos
import seaborn as sns
# A cor vem do campo `species` do dataframe
sns.pairplot(df, hue='species', height=5)
plt.show()

Desafio 5¶
Com base nos scatter plot, scatter matrix e pairplot, responda:
Crie um scatter plot para o comprimento e a largura das sépalas (sepal length vs. sepal width). Existe alguma relação aparente entre essas duas variáveis?
Compare os scatter plots do comprimento das pétalas (petal length) versus largura das pétalas (petal width) para cada espécie de Iris. Qual espécie parece ter a relação mais forte entre essas duas características?
Observe o scatter plot do comprimento das sépalas (sepal length) versus comprimento das pétalas (petal length). Existe algum padrão distinto que você pode identificar?
Com base no scatter plot da largura das sépalas (sepal width) versus largura das pétalas (petal width), existe alguma tendência que possa ajudar na classificação das espécies de Iris?
Como você usaria os padrões identificados nos scatter plots para diferenciar entre as espécies de Iris?
### Suas Respostas........
Violin¶
O Violin plot é similar ao box plot, exibe a distribuição de variaveis numéricas em niveis, pode ser configurada de muitas formas e é uma forma de visualização interessante de dados.
Saiba mais em: https://seaborn.pydata.org/generated/seaborn.violinplot.html
# Violin plot
g = sns.violinplot(y='species', x='sepal_length', data=df, inner='quartile')
plt.show()
g = sns.violinplot(y='species', x='sepal_width', data=df, inner='quartile')
plt.show()
g = sns.violinplot(y='species', x='petal_length', data=df, inner='quartile')
plt.show()
g = sns.violinplot(y='species', x='petal_width', data=df, inner='quartile')
plt.show()




Correlação entre atributos¶
A matriz de correlação avalia a relação entre duas ou mais variaveis (correlação).
valores:
- 0.9 a 1 positivo ou negativo indica uma correlação muito forte.
- 0.7 a 0.9 positivo ou negativo indica uma correlação forte.
- 0.5 a 0.7 positivo ou negativo indica uma correlação moderada.
- 0.3 a 0.5 positivo ou negativo indica uma correlação fraca.
- 0 a 0.3 positivo ou negativo indica uma correlação desprezível.
lembre-se que: alta correlação não implica em causa. (causa e consequência). Para entender melhor vale a pena dar uma olhada nesse site que mostra correlações absurdas...'spurious correlations'
cols = ['sepal_length', 'sepal_width', 'petal_length','petal_width']
corr_matx = df[cols].corr()
heatmap = sns.heatmap(corr_matx,cbar=True,annot=True,square=True,fmt='.2f',annot_kws={'size': 15},yticklabels=cols,xticklabels=cols,cmap='Dark2')

Desafio 6¶
Analise os gráficos gerados até o momento para responder as questões abaixo:
A especie que possui na média a menor sepala é a mesma que possui a menor petala?
Existe sobreposição entre as medições, ou seja, uma petala de tamanho x pode ser tanto da especie versicolor ou da virginica?
É possivel classificar as especies de iris com base apenas em suas dimensões?
### Implemente sua solução e apresente sua análise....
Acessando dados de um Dataframe¶
Há várias maneiras de acessar o conteúdo de um DataFrame. Os mais simples são aqueles que usam a notação de colchetes.
Primeiramente, podemos acessar uma coluna através do seu índice, retornando uma Series, ou seja, uma coluna do dataframe.
df['petal_length'].head()
0 1.4 1 1.4 2 1.3 3 1.5 4 1.4 Name: petal_length, dtype: float64
Por outro lado, se dentro dos colchetes passamos uma lista de nomes de coluna, o reultado é outro DataFrame contendo aquelas colunas. Isso vale inclusive para uma coluna simples:
# Mostra apenas a coluna petal_len
df[['petal_length']].head()
| petal_length | |
|---|---|
| 0 | 1.4 |
| 1 | 1.4 |
| 2 | 1.3 |
| 3 | 1.5 |
| 4 | 1.4 |
# Mostra as colunas petal_length e petal_width
df[['petal_length', 'petal_width']].head()
| petal_length | petal_width | |
|---|---|---|
| 0 | 1.4 | 0.2 |
| 1 | 1.4 | 0.2 |
| 2 | 1.3 | 0.2 |
| 3 | 1.5 | 0.2 |
| 4 | 1.4 | 0.2 |
# Criando uma nova característica: área da sépala
df['sepal_area'] = df['sepal_length'] * df['sepal_width']
df.head()
| sepal_length | sepal_width | petal_length | petal_width | species | sepal_area | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa | 17.85 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa | 14.70 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa | 15.04 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa | 14.26 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa | 18.00 |
Desafios 7¶
- Limpeza de Dados: Introduza valores faltantes no dataset Iris. Tente usar diferentes métodos para tratar essas imperfeições e compare os resultados.
- Manipulação de Dados: Use as funções do pandas para responder às seguintes perguntas sobre o dataset Iris:
- Qual é a média da largura da sépala para cada espécie?
- Quantas flores têm uma área da sépala maior que 20 cm^2?
- feature engineering: Pense em outras características que podem ser criadas a partir do dataset Iris. Por exemplo, uma característica que represente a proporção entre a largura e o comprimento da sépala.
## suas respostas aqui.....
Desafio 8¶
Faça agora uma exploração de dados em outra base, conheça a base, e crie hipoteses de teste.
- Importar os dados do dataset
Breast Cancer Data Setacesse o site:https://archive.ics.uci.edu/ml/datasets/breast+cancer - Nomear as colunas de acordo com o arquivo
breast-cancer.names - Ralizar a Análise Exploratória de Dados (EDA):
- Visualize a distribuição de cada característica do conjunto de dados.
- Determine quais características têm maior correlação com a classificação de malignidade.
- Crie novas características a partir das existentes.
- Crie representaçãoes gráficas do dataset para contribuir para sua análise
### Implemente sua sua solução e análise de dados. :)